写在前面
Tddl是一个分布式数据库中间件,它在阿里内部被广泛的使用,主要是为了解决分布式数据库产生的相关问题,分布式数据库与数据库中间件息息相关
演变历史
1)TDDL 2.0 (2009~2011) 第一个流行版本
2)TDDL 3.1 (2012~) 规则版本升级
3)TDDL 3.3 (2013~) 引入druid链接池
4)Andor (2012~2013) 一次全新的尝试,支持跨库查询
5)TDDL 5.0 (2013) 基于Andor + TDDL3.3的发展而来,保留各自的优点
6)TDDL 5.1 (2014~) 集成cobar,提供server模式,解决跨语言查询
组件架构
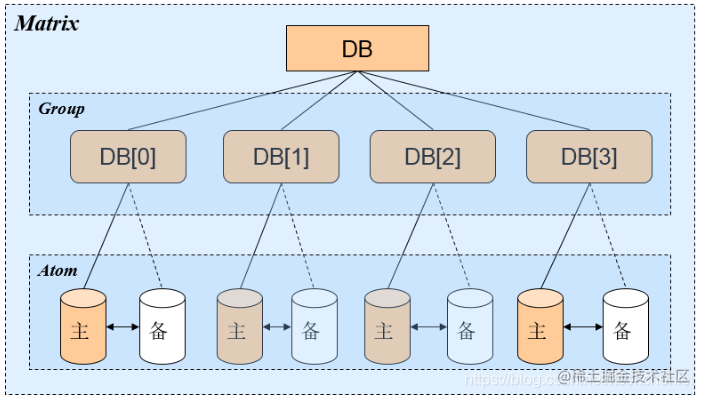
Matrix 层
Matrix 层可以解决分库分表带来的问题,从本质上来看,分库分表带来的最直接的影响是数据访问的路由。常见的数据访问路由算法有以下几种:
- 固定哈希算法,基本能保证数据均匀分布,它也是 TDDL 的默认路由算法。根据某个字段(如整形的 id 或者字符串的 hashcode)对分库的数量或者分表的数量进行取模,根据余数路由到对应的位置。
- 一致性哈希算法,固定哈希算法带来的数据迁移成本是非常大的,而一致性哈希算法的原理就是通过该算法计算出 key 的 hashcode 之后对 2^32 取模,那么数据都会落在 0~2^32 所组成的环中,然后数据存储在顺时针方向最近的机器上。一致性哈希已经可以解决大部分数据迁移需求了,但是对于数据集中在热点的情况,一致性哈希同样面临比较大的挑战,引入虚拟节点之后,情况就不一样了,所谓虚拟节点,它就是物理节点的映射,一个物理节点可以复制出多个虚拟节点,尽可能的让它均匀分布在环上,那么即使数据再集中,很好地起到了负载均衡的作用。
- 自定义路由规则,TDDL 也支持
Matrix 层除了要解决数据访问路由问题之外,还需要顺带提供其他的功能(围绕着数据访问路由这个功能展开的):
- 规则的管理(上面讲过)
- SQL语句的解释、优化和执行
- 各个子表查询出来结果集的Merge
- 事务的管理
Group 层
中间的数据库层,是逻辑上的各个数据库节点,这层的作用在于数据库读写分离,功能特性:
- 数据库读写分离
- 主备切换
- 权重的选择(根据权重选择要去读哪些库)
- 数据保护,数据库down掉后的线程保护, 数据库挂掉后的线程保护,不会因为一个数据库挂掉导致所有线程卡死。
Atom 层
底层数据源的管理,主要功能是:
- 动态创建,添加,减少数据源
- 底层对物理数据库做了代理,对单库的JDBC做了一层封装,执行底层单库的SQL
- 统计计数(线程数、执行次数)
读写分离
读写分离最大的问题是数据复制,通常有两种方式
- 镜像复制:即主库和从库的数据结构是一模一样的,通常根据主库上的日志变化,在从库中执行相同的操作
- 非对称复制:主库与备库是以不同的方式分库的,它们的结构虽然相同,但是主备库中存储的记录是不相同的。为何要这样设计?主要是查询条件不同时,把请求分发到更加适合的库去操作。在TDDL中,数据复制使用了中间件愚公,真是个好名字。比如:对于订单数据库,买家会根据自己的 ID 去查自己的交易记录,所以主库可以用买家 ID 分库,保证单个买家的记录在同一个数据库中。但是卖家如果想看交易记录的话可能就得从多个库中进行查询,这时候可以利用卖家 ID 进行分库作为备库,这样一来主备库的复制就不能简单的镜像复制了
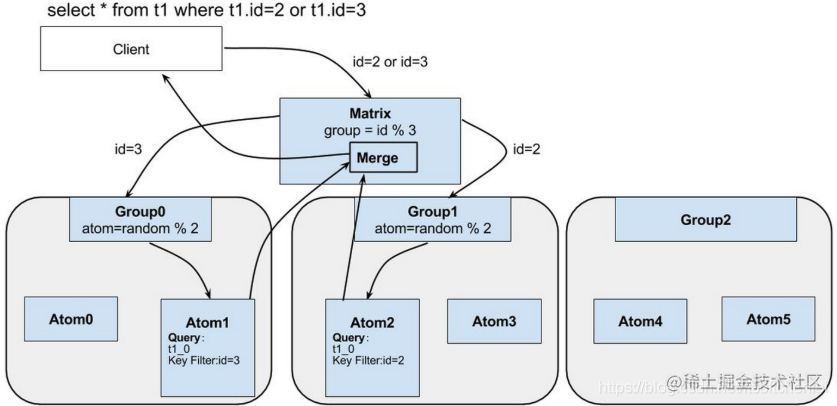
执行流程
client发送一条SQL的执行语句,会优先传递给Matrix层。由Martix 解释 SQL语句,优化,并根据查询条件路由到各个group,转发sql进行查询,各个group根据权重选择其中一个Atom进行查询,各个Atom再将结果返回给Matrix,Matrix将结果合并返回给client。
总结
其实TDDL原理也没有多复杂,都是基本思路,但是相信实现起来肯定是很复杂的,会遇到很多问题。而且TDDL还有很多其他功能,像sql解析、拆分、优化等,感兴趣的可以自己去学习。



