1 ElasticSearch概述
1.1 ElasticSearch是一个基于Lucene的搜索服务器
它提供了一个分布式多用户能力的全文搜索引擎,基于RESTfulweb接口。ElasticSearch是用Java开发的,
并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。构建在全
文检索开源软件Lucene之上的Elasticsearch,不仅能对海量规模的数据完成分布式索引与检索,还能提供数据聚合分析。据国际权威的 数据库产品评测机构DBEngines的统计,在2016年1月,Elasticsearch已超过Solr等,成为排名第一的搜索引擎类应用
概括:基于Restful标准的高扩展高可用的实时数据分析的全文搜索工具
1.2 ElasticSearch的基本概念
Index
类似于mysql数据库中的database
Type
类似于mysql数据库中的table表,es中可以在Index中建立type(table),通过mapping进行映射。
Document
由于es存储的数据是文档型的,一条数据对应一篇文档即相当于mysql数据库中的一行数据row, 一个文档中可以有多个字段也就是mysql数据库一行可以有多列。
Field
es中一个文档中对应的多个列与mysql数据库中每一列对应
Mapping
可以理解为mysql或者solr中对应的schema,只不过有些时候es中的mapping增加了动态识别功能,感觉很强大的样子, 其实实际生产环境上不建议使用,最好还是开始制定好了对应的schema为主。
Indexed
就是名义上的建立索引。mysql中一般会对经常使用的列增加相应的索引用于提高查询速度,而在es中默认都是会加 上索引的,除非你特殊制定不建立索引只是进行存储用于展示,这个需要看你具体的需求和业务进行设定了。
Query DSL
类似于mysql的sql语句,只不过在es中是使用的json格式的查询语句,专业术语就叫:QueryDSL
GET/PUT/POST/DELETE
分别类似与mysql中的select/update/delete
1.3 Elasticsearch的架构
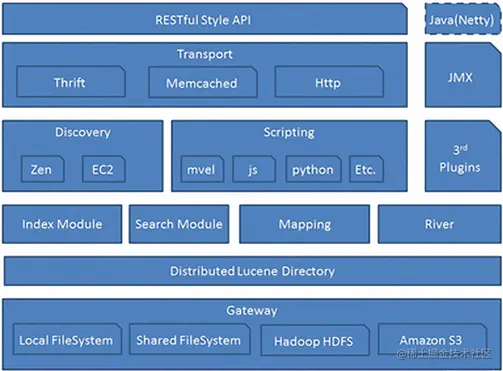
Gateway层
es用来存储索引文件的一个文件系统且它支持很多类型,例如:本地磁盘、共享存储(做snapshot的时候需要用到)、hadoop的hdfs分布式存储、亚马逊的S3。它的主要职责是用来对数据进行长持久化以及整个集群重启之后可以通过gateway重新恢复数据。
Distributed Lucene Directory
Gateway上层就是一个lucene的分布式框架,lucene是做检索的,但是它是一个单机的搜索引擎,像这种es分布式搜索引擎系统,虽然底层用lucene,但是需要在每个节点上都运行lucene进行相应的索引、查询以及更新,所以需要做成一个分布式的运行框架来满足业务的需要。
四大模块组件
districted lucene directory之上就是一些es的模块
- 1.Index Module是索引模块,就是对数据建立索引也就是通常所说的建立一些倒排索引等;
- 2.Search Module是搜索模块,就是对数据进行查询搜索;
- 3.Mapping模块是数据映射与解析模块,就是你的数据的每个字段可以根据你建立的表结构 通过mapping进行映射解析,如果你没有建立表结构,es就会根据你的数据类型推测你
的数据结构之后自己生成一个mapping,然后都是根据这个mapping进行解析你的数据; - 4.River模块在es2.0之后应该是被取消了,它的意思表示是第三方插件,例如可以通过一
些自定义的脚本将传统的数据库(mysql)等数据源通过格式化转换后直接同步到es集群里,
这个river大部分是自己写的,写出来的东西质量参差不齐,将这些东西集成到es中会引发
很多内部bug,严重影响了es的正常应用,所以在es2.0之后考虑将其去掉。
Discovery、Script
es4大模块组件之上有 Discovery模块:es是一个集群包含很多节点,很多节点需要互相发现对方,然后组成一个集群包括选主的,这些es都是用的discovery模块,默认使用的是Zen,也可是使用EC2;es查询还可以支撑多种script即脚本语言,包括mvel、js、python等等。
Transport协议层
再上一层就是es的通讯接口Transport,支持的也比较多:Thrift、Memcached以及Http,默认的是http,JMX就是java的一个远程监控管理框架,因为es是通过java实现的。
RESTful接口层
最上层就是es暴露给我们的访问接口,官方推荐的方案就是这种Restful接口,直接发送http请求,方便后续使用nginx做代理、分发包括可能后续会做权限的管理,通过http很容易做这方面的管理。如果使用java客户端它是直接调用api,在做负载均衡以及权限管理还是不太好做。
1.4 RESTful API
一种软件架构风格、设计风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。
基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。在目前主流的三种Web服务交互方案中,REST相比于S
OAP(Simple Object Access protocol,简单对象访问协议)以及XML-RPC更加简单明了
sql复制代码
(Representational State Transfer 意思是:表述性状态传递)
它使用典型的HTTP方法,诸如GET,POST.DELETE,PUT来实现资源的获取,添加,修改,删除等操作。
即通过HTTP动词来实现资源的状态扭
GET 用来获取资源
POST 用来新建资源(也可以用于更新资源)
PUT 用来更新资源
DELETE 用来删除资源
1.5 CRUL命令
以命令的方式执行HTTP协议的请求
GET/POST/PUT/DELETE
示例:
访问一个网页
curl www.baidu.com
curl -o tt.html www.baidu.com
显示响应的头信息
curl -i www.baidu.com
显示一次HTTP请求的通信过程
curl -v www.baidu.com
执行GET/POST/PUT/DELETE操作
curl -X GET/POST/PUT/DELETE url
2. ElasticSearch基本操作
2.1 倒排索引
Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
下面通过一个示例来认识倒排索引
(1):假设文档集合包含五个文档,每个文档内容如图所示,在图中最左端一栏是每个文档对应的文档编号。我们的任务就是对这个文档集合建立倒排索引。

(2):中文和英文等语言不同,单词之间没有明确分隔符号,所以首先要用分词系统将文档自动切分成单词序列。这样每个文档就转换为由单词序列构成的数据流,为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引
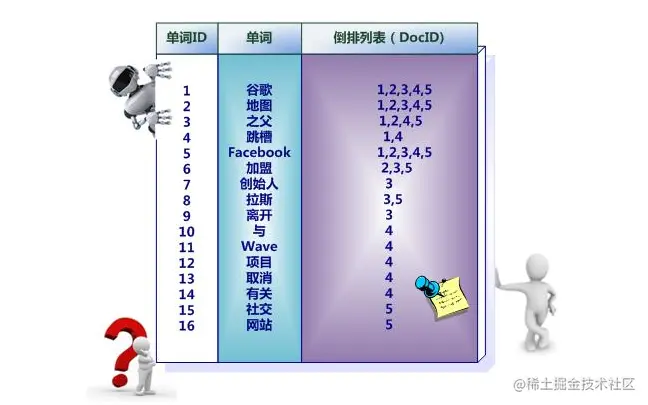
“单词ID”一栏记录了每个单词的单词编号,第二栏是对应的单词,第三栏即每个单词对应的倒排列表
(3):索引系统还可以记录除此之外的更多信息,下图还记载了单词频率信息(TF)即这个单词在某个文档中的出现次数,之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子,所以将其记录在倒排列表中,以方便后续排序时进行分值计算。

(4):倒排列表中还可以记录单词在某个文档出现的位置信息
(1,<11>,1),(2,<7>,1),(3,<3,9>,2)
有了这个索引系统,搜索引擎可以很方便地响应用户的查询,比如用户输入查询词“Facebook”,搜索系统查找倒排索引,从中可以读出包含这个单词的文档,这些文档就是提供给用户的搜索结果,而利用单词频率信息、文档频率信息即可以对这些候选搜索结果进行排序,计算文档和查询的相似性,按照相似性得分由高到低排序输出,此即为搜索系统的部分内部流程。
2.2 什么是Mapping
mapping定义了type中的每个字段的数据类型以及这些字段如何分词等相关属性
创建索引的时候,可以预先定义字段的类型以及相关属性,这样就能够把日期字段处理成日期,把数字字段处理成数字,把字符串字段处理字符串值等
支持的数据类型
- 核心数据类型(Core datatypes)
字符型:string,string类型包括
text 和 keyword
text类型被用来索引长文本,在建立索引前会将这些文本进行分词,转化为词的组合,建立索引。允许es来检索这些词语。text类型不能用来排序和聚合。
Keyword类型不需要进行分词,可以被用来检索过滤、排序和聚合。keyword 类型字段只能用本身来进行检索
数字型:long, integer, short, byte, double, float
日期型:date
布尔型:boolean
二进制型:binary- 复杂数据类型(Complex datatypes)
数组类型(Array datatype):数组类型不需要专门指定数组元素的type,例如:
字符型数组: [ "one", "two" ]
整型数组:[ 1, 2 ]
数组型数组:[ 1, [ 2, 3 ]] 等价于[ 1, 2, 3 ]
对象数组:[ { "name": "Mary", "age": 12 }, { "name": "John", "age": 10 }]
对象类型(Object datatype):_ object _ 用于单个JSON对象;
嵌套类型(Nested datatype):_ nested _ 用于JSON数组;- 地理位置类型(Geo datatypes)
地理坐标类型(Geo-point datatype):_ geo_point _ 用于经纬度坐标;
地理形状类型(Geo-Shape datatype):_ geo_shape _ 用于类似于多边形的复杂形状;
- 特定类型(Specialised datatypes)
IPv4 类型(IPv4 datatype):_ ip _ 用于IPv4 地址;
Completion 类型(Completion datatype):_ completion _提供自动补全建议;
Token count 类型(Token count datatype):_ token_count _ 用于统计做了标记的字段的index数目,该值会一直增加,不会因为过滤条件而减少。
mapper-murmur3
类型:通过插件,可以通过 _ murmur3 _ 来计算 index 的 hash 值;
附加类型(Attachment datatype):采用 mapper-attachments
插件,可支持_ attachments _ 索引,例如 Microsoft Office 格式,Open Document 格式,ePub, HTML 等。
支持的属性
- “store”:false//是否单独设置此字段的是否存储而从_source字段中分离,默认是false,只能搜索,不能获取值
- “index”: true//分词,不分词是:false,设置成false,字段将不会被索引
- “analyzer”:”ik”//指定分词器,默认分词器为standard analyzer
- “boost”:1.23//字段级别的分数加权,默认值是1.0
- “doc_values”:false//对not_analyzed字段,默认都是开启,分词字段不能使用,对排序和聚合能提升较大性能,节约内存
- “fielddata”:{“format”:”disabled”}//针对分词字段,参与排序或聚合时能提高性能,不分词字段统一建议使用doc_value
- “fields”:{“raw”:{“type”:”string”,”index”:”not_analyzed”}} //可以对一个字段提供多种索引模式,同一个字段的值,一个分词,一个不分词
- “ignore_above”:100 //超过100个字符的文本,将会被忽略,不被索引
- “include_in_all”:ture//设置是否此字段包含在_all字段中,默认是true,除非index设置成no选项
- “index_options”:”docs”//4个可选参数docs(索引文档号) ,freqs(文档号+词频),positions(文档号+词频+位置,通常用来距离查询),offsets(文档号+词频+位置+偏移量,通常被使用在高亮字段)分词字段默认是position,其他的默认是docs
- “norms”:{“enable”:true,”loading”:”lazy”}//分词字段默认配置,不分词字段:默认{“enable”:false},存储长度因子和索引时boost,建议对需要参与评分字段使用 ,会额外增加内存消耗量
- “null_value”:”NULL”//设置一些缺失字段的初始化值,只有string可以使用,分词字段的null值也会被分词
- “position_increament_gap”:0//影响距离查询或近似查询,可以设置在多值字段的数据上火分词字段上,查询时可指定slop间隔,默认值是100
- “search_analyzer”:”ik”//设置搜索时的分词器,默认跟ananlyzer是一致的,比如index时用standard+ngram,搜索时用standard用来完成自动提示功能
- “similarity”:”BM25”//默认是TF/IDF算法,指定一个字段评分策略,仅仅对字符串型和分词类型有效
- “term_vector”:”no”//默认不存储向量信息,支持参数yes(term存储),with_positions(term+位置),with_offsets(term+偏移量),with_positions_offsets(term+位置+偏移量) 对快速高亮fast vector highlighter能提升性能,但开启又会加大索引体积,不适合大数据量用



