0 写在前面
本文主要是收录了一些大厂面试经验,题目涉及Go语言基础知识、数据库知识、消息队列、Kubernetes相关知识、服务治理与微服务架构、Docker知识、监控和度量、算法与编程、自我介绍、职业规划等。
1 Go语言基础
- 问题1:Go的垃圾回收机制?GMP模型?(展盟,百度,滴滴,小米)
1.Go的垃圾回收是三色标记法。主要步骤如下:
- a. 首先把所有对象放入白色集合中
- b. 把所有根节点放入灰色集合中
- c. 遍历所有灰色集合中的对象,将它放入黑色集合中。并且把灰色集合中对象能够访问到的白色集合中的对象放到灰色集合中
- d. 重复步骤c,直到灰色集合为空
- e. 这个时候白色集合中的对象就是需要回收的。调用垃圾回收程序进行回收。
步骤b中提到的根节点包含哪些呢?下面是chatgpt的回答
在 Go 的三色标记垃圾回收算法中,根节点是指程序中可直接访问的变量,包括全局变量、当前运行函数的参数和局部变量、当前 Goroutine 的栈变量、当前 Goroutine 正在执行的函数参数和局部变量、正在被其它 Goroutine 所访问的变量等。
换句话说,根节点是指程序中的所有活跃对象的起始点,GC 会从这些根节点开始遍历,找到所有从根节点可达的对象,并标记为活跃对象,未标记的对象则被认为是垃圾,最终被回收。关于go垃圾回收可看另外一篇文章go 垃圾回收那些事儿
2.GMP模型是go语言运行时协程管理和调度的模型。
- G(goroutine):代表一个轻量级线程,包含了执行goroutine所需的栈信息和相关状态。
- M(machine):代表一个线程上下文,包括线程的调度信息、当前执行的goroutine等。
- P(processor):代表一个逻辑处理器,负责调度goroutine到线程M上执行,并管理goroutine的运行队列。
关于go协程管理可看另外一篇文章Go协程管理
- 问题2:Golang如何优雅关闭一个channel?(展盟)
调用
close()函数关闭channel,一般在哪个goroutine定义channel就在那个gorountine关闭,不要在其他gorountine关闭channel,因为当有多个gorountine的时候,不知道其他goroutine是否已经关闭了channel,关闭一个已经关闭的channel会导致gorountine panic。
- 问题3:Go里面的map是怎么决绝hash冲突的?(展盟)
go的map底层是一个数组,数组每个原始是一个桶,采用拉链法解决hash冲突
go map结构如下:
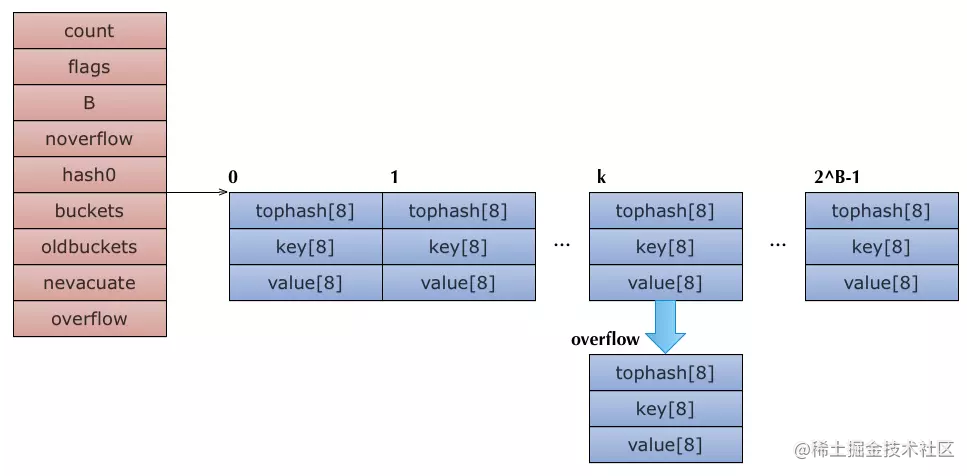
关于go协程管理可看另外一篇文章go map那些事儿
- 问题4:slice是引用传递还是值传递?slice 参数传递过去,修改之后,外部变量是否也会被修改?(展盟)
go的函数传参,没有引用传递,全都是值传递,即所有参数都是复制一遍,在函数内部是一个新的对象,根函数外面不是同一个对象,它有新的内存地址。
但是在函数内部有时候是可以修改入参的,这是因为入参内部是引用类型,在函数内部修改引用类型的值肯定会修改原来的对象,函数入参复制的只是对象,对象内部属性的值还是一样的。例如:
原因:type Teacher struct{ name string } type Student struct{ name string teacher *Teacher } func main(){ t1:= &Teacher{name:"zhangsan"} s1:=Student{name:"lisi",teacher:t1} t(s1) fmt.Printf("s1.name:%s, t1.name:%s", s1.name, t1.name) } func t(s Student){ s.name="lisi111" s.teacher.name="zhangsan222" // s1.name:lisi, t1.name:zhangsan222 }t()函数的入参是Student类型,t(s1)会将s1复制一遍,所以t()函数内部修改s1.name不会改变main()函数中s1的name;但是Student中teacher是个指针类型,main()函数中的s1与t()函数中的s虽然是2个不同的变量,但是他们的teacher字段的值是一样的,都指向main()函数的t1对象的内存地址,所以在t()函数中修改s.teacher.name字段会改变main()函数中t1.name。
再来说说slice 参数传递过去,修改之后,外部变量是否也会被修改。这个问题的答案是:可能会修改,也可能不会修改。
先看看下面这段代码
func testSlice1(arr []int) {
arr[0] = 3
arr[1] = 4
}
func testSlice2(arr []int) {
arr = append(arr, 5, 6, 7, 8, 9, 10)
arr[0] = 3
arr[1] = 4
}
func testSlice3(arr []int) {
arr[0] = 3
arr[1] = 4
arr = append(arr, 5, 6, 7, 8, 9, 10)
}
func main() {
arr1 := []int{1, 2}
testSlice1(arr1)
fmt.Println(arr1) // [3 4]
arr2 := []int{1, 2}
testSlice2(arr2)
fmt.Println(arr2) // [1 2]
arr3 := []int{1, 2}
testSlice3(arr3)
fmt.Println(arr3) // [3 4]
}分析
- 1.testSlice1修改了arr slice底层指向的数组,因此输出:[3,4],容易理解。
- 2.testSlice2先是像arr slice中增加6个元素,这个操作导致arr底层指向的数组发生了变化,但是arr作为参数传进来是值传递,因此这次扩容虽然修改了入参arr底层指向的数组,但是不影响main函数中的arr2,所以该函数后面修改arr[0],arr[1]并不会改变main的arr2,因此输出:[1,2]
- 3.testSlice3先修改了arr slice底层指向的数组元素,跟testSlice1一样,会改变main函数中的arr3,后面向arr中追加6个元素,导致arr底层指向的数组发生了改变,因为arr是值传递,不会改变main的arr3,因此输出:[3,4]
关于go slice可看另外一篇文章在函数内部能修改入参slice吗?不一定
问题5:Go读写锁的概念?读的时候会影响别人的读么?读优先还是写优先?(展盟)
在Go语言的sync包中,Mutex(互斥锁)和RWMutex(读写锁)都是用来管理对共享资源的访问的机制,但它们之间有一些重要的区别
互斥锁(Mutex):
互斥锁是最基本的锁类型,它在同一时刻只允许一个goroutine访问共享资源。
当一个goroutine获得了互斥锁后(通过调用Lock方法),其他goroutine就无法再获取到该锁,直到持有锁的goroutine释放了它(通过调用Unlock方法)。
互斥锁适用于对共享资源的写操作或者需要排他性访问的场景。读写锁(RWMutex):
读写锁允许多个goroutine同时对共享资源进行读取操作,但在写操作时会阻塞其他goroutine对资源的读写操作。
当一个goroutine获得了读锁后(通过调用RLock方法),其他goroutine仍可以获取该读锁,从而进行并发的读操作。但当有goroutine持有写锁时,其他goroutine无法获取读锁或写锁,直到写锁被释放。
写锁是排他的,一旦有goroutine持有写锁,其他goroutine无法获取读锁或写锁,直到写锁被释放。问题6:context的应用场景?(展盟)
1.函数传参,传递上下文。context中可以放一些公共资源,比如在中间件中放一些用户信息、缓存信息等等。
2.gorountine之间传递信息、控制goroutine的执行。
关于go context可看另外一篇文章一文读懂go context
- 问题7:select的作用?项目中怎么使用的?(展盟)
在 Go 语言中,select 语句用于在多个通信操作中进行选择。通常用于处理并发操作,例如等待多个 channel 中的消息到达或者执行超时操作。select 语句使得 Goroutine 能够同时等待多个 channel 上的操作,一旦其中一个 channel 准备好了,就会执行对应的分支。
在项目中,select 通常用于以下情况:
多路复用:当需要同时等待多个 channel 的消息到达时,使用 select 可以避免阻塞,使得 Goroutine 能够及时响应不同的事件。
超时控制:通过 select 结合 time.After 或者自定义的超时 channel,可以实现对某些操作的超时控制,避免因为某个操作耗时过长而导致整个程序阻塞。
优雅退出:在需要结束 Goroutine 的情况下,可以使用 select 结合一个退出 channel,通过向该 channel 发送信号来通知 Goroutine 安全退出。
控制流程:根据不同的 channel 状态执行不同的操作,例如处理请求队列、事件监听等。
关于go select的原理可看另外一篇文章GO-select 的实现原理
问题8:数组和切片的区别(柯莱特-外派小红书,优咔科技)
Go语言中的数组(Array)和切片(Slice)是两种不同的数据类型,它们有一些重要的区别:
1.长度固定 vs 动态长度:数组是具有固定长度的数据结构。在声明数组时,必须指定其长度,并且数组的长度在整个程序生命周期内保持不变。
切片是一个动态长度的数据结构。它是对数组的一个引用,可以根据需要动态增长或缩小。切片的长度和容量可以在运行时进行修改。
2.内存分配方式:- 数组是在声明时就分配好内存空间的。因为数组长度固定,所以在内存中的布局也是固定的。
- 切片是在运行时动态分配内存的。切片只是一个轻量级的引用类型,实际的数据存储在底层数组中。
3.传递方式:
- 数组在函数间传递时通常是按值传递的,即传递的是数组的副本,这可能会导致性能开销较大,尤其是对于大型数组。
- 切片在函数间传递时是按引用传递的,即传递的是切片的指针,因此函数间操作同一个底层数组的切片会影响到彼此的结果。
4.灵活性:
- 数组长度固定,因此在某些情况下可能会限制灵活性,特别是在处理动态数据集时。
- 切片具有动态长度,可以根据需要动态增长或缩小,因此更灵活,适用于处理不确定大小的数据集。
总的来说,数组适合用于长度固定且元素类型相同的情况,而切片则更适用于需要动态管理数据、长度不确定或会发生变化的情况。在实际项目中,切片的使用更为常见,因为它提供了更多的灵活性和便利性。
问题9:map是否是线程安全的,如何在Go中使用线程安全的map(柯莱特-外派小红书,优咔科技)
go map不是线程安全的,如果想要线程安全,可以用sync包提供的Map
sync.Map 是 Go 语言标准库 sync 包提供的一种线程安全的 map 实现。它提供了一种高效的并发安全的键值对存储和检索机制,适用于多个 goroutine 同时访问的场景。原理
sync.Map 的实现原理是通过分片(sharding)和原子操作来实现并发安全的键值对存储和检索。具体来说,sync.Map 内部维护了一个固定数量的分片,每个分片对应一个散列表,用于存储键值对。在对 sync.Map 进行操作时,会根据键的哈希值选择相应的分片,然后在该分片上执行操作。
初始化分片: 在创建 sync.Map 实例时,会初始化一定数量的分片,默认情况下是 32 个分片。每个分片是一个散列表,用于存储键值对。
哈希映射: 当执行存储、加载、删除等操作时,会根据键的哈希值选择相应的分片,然后在该分片上执行相应的操作。这样可以将并发操作在多个分片上分散开来,减小了锁的粒度,提高了并发性能。
分片锁: 每个分片都有一个读写锁(sync.RWMutex),用于保护该分片内的键值对数据。在执行操作之前,会先获取相应分片的锁,以确保并发安全性。
原子操作: 在对分片执行存储、加载、删除等操作时,会使用原子操作来确保多个 goroutine 之间的同步。这样可以避免传统 map 在并发访问时可能出现的竞态条件问题。
性能优化: sync.Map 内部实现了一些性能优化策略,例如分片数量固定、懒初始化等,以提高并发性能和降低内存消耗。
- 问题10:sync.map的原理(柯莱特-外派小红书,优咔科技)
见问题9
- 问题11:Go数据类型有哪些?(优咔科技)
Go 语言中的数据类型主要分为基本类型和复合类型两类。下面是 Go 语言中常见的数据类型:
基本类型:
- 整数类型(Integer types):包括 int8、int16、int32、int64、uint8、uint16、uint32、uint64 和 int、uint(根据操作系统位数而定)等。
- 浮点数类型(Floating-point types):包括 float32 和 float64。
- 复数类型(Complex types):包括 complex64 和 complex128。
- 布尔类型(Boolean types):只有两个值,true 和 false。
- 字符串类型(String types):表示字符串值的序列,用双引号或反引号括起来。
- 字节类型(Byte types):别名为 byte,实际上是 uint8 的别名。
- 符文类型(Rune types):别名为 rune,实际上是 int32 的别名,用于表示 Unicode 码点。
复合类型:
- 数组类型(Array types):表示一组固定大小的相同类型的元素的序列。
- 切片类型(Slice types):表示一个动态大小的元素序列。
- 映射类型(Map types):表示键值对的无序集合。
- 结构体类型(Struct types):表示由零个或多个任意类型的字段组成的数据结构。
- 通道类型(Channel types):用于在 goroutine 之间进行通信的数据结构。
- 接口类型(Interface types):表示一组方法的集合,用于指定对象的行为。
- 函数类型(Function types):表示具有特定参数和返回值类型的函数。
- 指针类型(Pointer types):指向某个变量的内存地址。
- 问题12:如何判断两个interface{}相等?(优咔科技)
因为go中对象有类型和值两个属性,所以要比较两个对象是否相等,需要比较他们的类型是否相同以及值是否相同。
如果对象是结构体,甚至结构体内部还有指向其他结构体的指针,就需要根据需求决定,是否只需要判断指针是否相等还是需要递归判断指针指向的结构体内容是否相等。
- 问题13:Go map中删除一个key的内存是否会立即释放?(优咔科技)
不会立即删除,只会标记删除,后面由 Go 的垃圾回收器来处理。垃圾回收器会在某个时机检查并释放不再被引用的内存,包括被删除的键值对占用的内存。
优点
- 简单方便:使用 map 来管理数据时,可以方便地添加、查找和删除键值对,不需要手动管理内存。
- 性能高效:删除的时候只是标记一下,速度非常快。 Go 的垃圾回收器在后台运行,会定期检查和释放不再被引用的内存,不会影响程序的性能。
缺点
- 不可控制:内存的释放时机是由 Go 的垃圾回收器来控制的,我们无法控制何时释放内存,可能会导致一些临时性的内存占用。
- 可能导致内存占用过高:如果 map 中存在大量的键值对,而垃圾回收器的运行频率又不够高,可能会导致内存占用过高,影响程序的性能。
- 问题14:init()方法的特性(优咔科技)
init() 函数是 Go 语言的一个特殊函数,它可以在程序执行之前被自动调用,用于初始化程序的状态或执行一些预处理操作。init() 函数具有以下特性:
特殊性: init() 函数是一个特殊的函数,它没有参数,也没有返回值,且不能被显式调用。它由 Go 运行时在程序开始执行之前自动调用。
执行顺序
- 当前包的常量初始化
- 当前包的变量初始化
- 引入包(按照import的逆序执行),引入包中也是按照:常量初始化、变量初始化、引入包、init、main的执行顺序
- 执行当前包的init
- 执行当前包的main
执行顺序在另外一篇文章有介绍GO 易考易错点
- 问题15:switch-case语句,强制执行下一个case(优咔科技)
可以在 case 中使用 fallthrough 关键字来强制执行下一个 case。
package main
import "fmt"
func main() {
var num int = 2
switch num {
case 1:
fmt.Println("这是 1")
fallthrough
case 2:
fmt.Println("这是 2")
fallthrough
case 3:
fmt.Println("这是 3")
}
}在上面的示例中,num 的值为 2,因此匹配到了 case 2。然后 fallthrough 关键字强制执行了下一个 case,即 case 3,因此输出了 “这是 2” 和 “这是 3”。
- 问题16:encoding/json 包解码通过 HTTP 请求接收的 JSON 数据时,它会默认将所有数字解析为 float64 类型(优咔科技)
在 Go 的 encoding/json 包中,默认情况下,当解码 JSON 数据时,所有的数字都会被解析为 float64 类型。这是因为 JSON 中的数字可以表示整数和浮点数,而 Go 中的 float64 类型可以容纳 JSON 中的所有数字类型,因此在解码时会将所有数字都解析为 float64 类型,以确保不会丢失精度
如果你希望将 JSON 中的数字解析为 Go 中的其他数字类型(例如 int、int64 等),你可以使用 json.Decoder 的 UseNumber 方法将其解析为 json.Number 类型,然后再根据需要将其转换为其他类型。示例代码如下:
package main
import (
"encoding/json"
"fmt"
"strings"
)
func main() {
// 模拟 HTTP 请求接收的 JSON 数据
jsonStr := `{"int_value":42,"float_value":3.14}`
// 创建 JSON 解码器
decoder := json.NewDecoder(strings.NewReader(jsonStr))
// 使用 UseNumber 方法将数字解析为 json.Number 类型
decoder.UseNumber()
// 定义结构体用于存储解析后的数据
var data struct {
IntValue int `json:"int_value"`
FloatValue float64 `json:"float_value"`
}
// 解码 JSON 数据
if err := decoder.Decode(&data); err != nil {
fmt.Println("解码失败:", err)
return
}
// 输出解析结果
fmt.Println("IntValue:", data.IntValue)
fmt.Println("FloatValue:", data.FloatValue)
}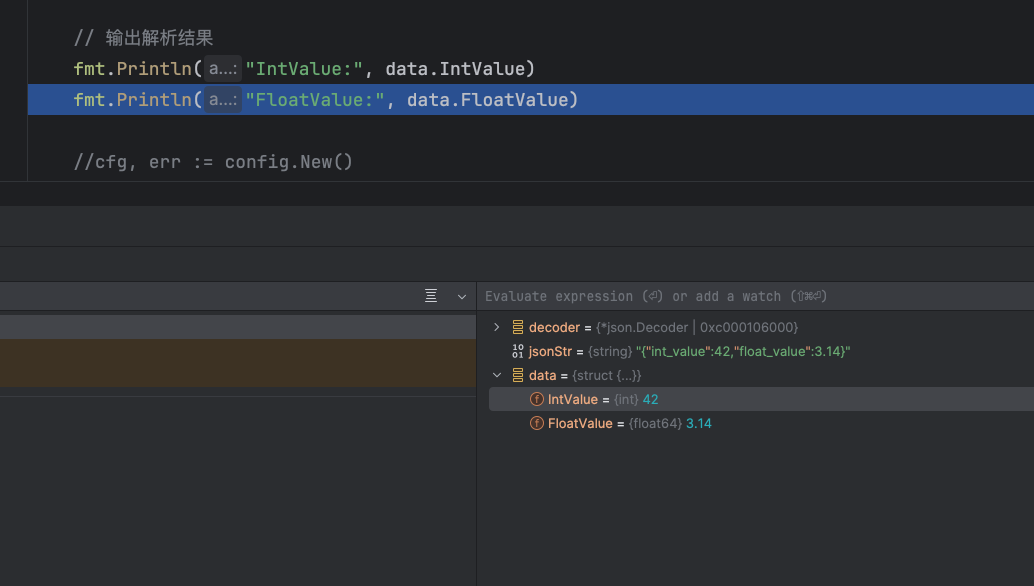
通过调试可以看到IntValue是int类型
- 问题17:Go里面的类型断言?(优咔科技)
类型断言是一种用于判断接口值的实际类型并提取其具体值的机制
应用场景
- 类型转换: 类型断言允许将接口值转换为具体的类型,从而可以对接口值进行类型特定的操作。这对于处理接口类型的数据非常有用,因为接口类型的数据在编译时是不知道其具体类型的
- 类型判断: 类型断言可以用于判断接口值是否实现了某个接口或具体的类型。这对于进行类型断言前的类型检查非常有用,可以避免在类型转换时触发 panic。
- 反射机制: 类型断言是反射机制的基础之一,在使用反射包时,通常需要先对接口值进行类型断言,然后才能获取其具体的类型信息和字段值。
- 问题18:Go静态类型声明?(优咔科技)
静态类型声明指的是在变量、常量、函数参数、函数返回值等地方显式地声明变量的类型。这种声明方式使得变量在编译时就确定了其类型,不允许在运行时改变类型
- 问题19:sync包使用?(优咔科技,360)
互斥锁(Mutex):
- Mutex 对象是最基本的同步原语,用于保护临界区,防止多个 goroutine 同时访问共享资源。
- Mutex 提供了 Lock() 和 Unlock() 方法用于加锁和解锁,确保在同一时刻只有一个 goroutine 能够访问共享资源。
读写锁(RWMutex):
- RWMutex 是一种更加灵活的同步原语,它区分了读操作和写操作,允许多个 goroutine 同时读取共享资源,但只允许一个 goroutine 写入共享资源。
- RWMutex 提供了 RLock()、RUnlock()、Lock() 和 Unlock() 方法,分别用于读锁定、读解锁、写锁定和写解锁。
等待组(WaitGroup):
- WaitGroup 用于等待一组 goroutine 完成任务,它可以追踪多个 goroutine 的完成状态,并在所有 goroutine 完成后通知调用者。
- WaitGroup 提供了 Add()、Done() 和 Wait() 方法,分别用于增加计数、减少计数和等待计数归零。
条件变量(Cond):
- Cond 是一种条件变量,用于在多个 goroutine 之间进行通信和同步。它可以在某个条件满足时通知等待的 goroutine。
- Cond 提供了 Signal()、Broadcast() 和 Wait() 方法,用于单个 goroutine 的唤醒、全部 goroutine 的唤醒和等待条件变量的信号。
- 问题20:gin的并发请求、错误处理、路由处理(优咔科技)
并发请求处理:
Gin 默认的 HTTP 服务器是使用 Go 标准库中的 net/http 包实现的,因此可以通过 Go 语言中的并发机制来处理并发请求。Gin 框架本身并没有对并发请求做特殊处理,而是利用 Go 语言的并发机制来处理请求,每个请求都会在独立的 goroutine 中执行,因此可以很容易地处理并发请求。错误处理:
Gin 框架提供了全局中间件机制来处理请求中出现的错误。可以通过在路由组上注册中间件来统一处理错误,例如,可以通过 gin.Recovery() 中间件来捕获并处理请求中的 panic,并返回一个 500 错误给客户端。除此之外,可以通过自定义中间件来处理其他类型的错误,例如身份验证错误、权限错误等。路由处理:
Gin 框架提供了丰富的路由处理功能,包括基本的路由匹配、参数解析、中间件等。通过定义路由处理函数,可以很方便地处理不同路径的 HTTP 请求。可以通过 GET、POST、PUT、DELETE 等方法来定义不同类型的路由,还可以通过 gin.Group 来定义路由组,实现路由的模块化管理。
- 问题21:CSP并发模型(百度)
CSP(Communicating Sequential Processes)是一种并发编程模型,由Tony Hoare在1978年提出
CSP 模型的核心思想是通过通信来共享数据,而不是共享内存
在 CSP 模型中,进程之间通过通道(Channel)进行通信,每个进程都是独立的并且是顺序执行的。这种模型避免了传统并发编程中常见的共享内存造成的数据竞争和死锁问题,提高了程序的可靠性和可维护性
进程(Process): 进程是 CSP 模型中的基本执行单元,每个进程都是独立的,并且是顺序执行的。进程之间通过通道进行通信。
通道(Channel): 通道是 CSP 模型中用于进程间通信的管道,可以用于在进程之间传递数据。通道是一种先进先出(FIFO)的数据结构,可以在多个进程之间传递消息。
通信(Communication): 进程之间通过通道进行通信,发送方将消息发送到通道中,接收方从通道中接收消息。通信是同步的,发送方和接收方必须同时准备好才能进行通信。
并发(Concurrency): CSP 模型支持并发执行多个进程,每个进程都是独立的并且是顺序执行的。通过通道进行通信和同步,可以实现进程之间的并发执行。
CSP 模型适用于需要高度并发和可靠性的场景,例如网络通信、并行计算等。在实际应用中,可以使用 CSP 模型来构建高效、可靠的并发系统,避免共享内存带来的问题,提高程序的性能和可维护性。在 Go 语言中,CSP 模型被广泛应用,通过 goroutine 和 channel 来实现并发编程,是 Go 语言并发编程的核心理念之一。
- 问题22:逃逸分析的介绍?逃逸分析怎么看(-gcflags = “-m -l”)?工作中是否用过逃逸分析解决问题?(百度)
逃逸分析(Escape Analysis)是编译器在编译阶段对程序中变量的分析过程,用于确定变量的生命周期是否超出了当前函数的作用域,从而决定变量是分配在堆上还是栈上。逃逸分析是编译器优化的一部分,可以帮助编译器更好地进行内存管理,提高程序的性能。
在 Go 语言中,可以通过 -gcflags=”-m -l” 参数来启用逃逸分析并打印逃逸分析的结果
栈上分配(Stack Allocation): 如果变量的生命周期仅限于当前函数作用域内,并且不会被函数之外的其他部分引用,那么编译器可以将该变量分配在栈上。栈上分配可以减少内存分配和垃圾回收的开销,提高程序的性能。
堆上分配(Heap Allocation): 如果变量的生命周期超出了当前函数作用域,或者变量被函数之外的其他部分引用,那么编译器必须将该变量分配在堆上。堆上分配需要额外的内存分配和垃圾回收的开销,但可以避免在函数调用结束后变量被销毁的问题。
关于go逃逸分析可以看另外一篇文章GO逃逸分析
- 问题23:对关闭的channel进行读写channel会发生什么?对关闭的channel写为什么会panic?(百度)
在 Go 中,对已关闭的通道进行读取操作不会引发 panic,而是会返回通道元素类型的零值和一个布尔值,指示通道是否已关闭。这种行为可以用于检测通道是否已关闭
在 Go 中,对已关闭的通道进行写入操作会导致运行时 panic。这是因为关闭通道后,通道的状态会被设置为关闭状态,写入操作会尝试向一个已关闭的通道发送数据。这是一个违反通道的语义规则的操作,因此会触发运行时错误。
种设计可以确保通道的语义和安全性,并防止在已关闭的通道上进行不正确的操作。
- 问题24:字符串转byte数组会发生内存拷贝么?为什么?(百度)
在 Go 中,字符串是不可变的,底层的字节数组存储了字符串的内容。当字符串转换为字节数组时,会发生内存拷贝,因为字节数组是可变的,而字符串是不可变的。
Go 的字符串底层数据结构包含两部分:指向存储字符串内容的指针和字符串的长度。当字符串被转换为字节数组时,会首先创建一个新的字节数组,然后将字符串的内容复制到该字节数组中。这样做是为了确保字符串的不可变性,因为字符串的内容可能会被修改,而字符串本身不应该被修改。
- 问题25:如何实现字符串转切片无内存拷贝(unsafe)?(百度)
在 Go 中,由于字符串和切片的底层数据结构不同,字符串转换为切片时会发生内存拷贝。然而,可以通过使用 unsafe 包中的指针操作来实现字符串转切片无内存拷贝,但是这种方法不够安全,因为它会绕过 Go 的内存管理机制,可能导致程序出现未定义的行为。
package main
import (
"fmt"
"reflect"
"unsafe"
)
func stringToBytes(s string) []byte {
strHeader := (*reflect.StringHeader)(unsafe.Pointer(&s))
sliceHeader := &reflect.SliceHeader{
Data: strHeader.Data,
Len: strHeader.Len,
Cap: strHeader.Len,
}
return *(*[]byte)(unsafe.Pointer(sliceHeader))
}
func main() {
str := "hello"
slice := stringToBytes(str)
fmt.Println(slice) // [104 101 108 108 111]
}
在上面的代码中,通过 unsafe.Pointer 和 reflect 包来获取字符串和切片的底层数据结构,并通过类型转换实现字符串转切片的操作。需要注意的是,这种方法是不安全的,因为它绕过了 Go 的类型系统和内存管理机制,可能导致程序出现未定义的行为,因此在实际开发中应尽量避免使用。
- 问题26:Go语言channel的特性?channel阻塞信息是怎么处理的?channel底层实现?(360)
Go 语言中的通道(channel)是一种并发安全的数据结构,用于在多个 goroutine 之间进行通信和同步。通道具有以下几个特性:
并发安全: 通道是并发安全的,多个 goroutine 可以安全地向通道发送和接收数据,而不需要额外的同步措施。
阻塞等待: 如果通道为空而尝试从通道接收数据,或者通道已满而尝试向通道发送数据,那么当前 goroutine 将被阻塞,直到通道变为非空或非满。
同步通信: 通道提供了同步的通信机制,发送和接收操作在发送方和接收方之间建立了同步关系,确保发送操作发生在接收操作之前。
有缓冲和无缓冲: 通道可以是有缓冲的或无缓冲的。无缓冲通道的容量为 0,发送操作会阻塞直到有 goroutine 准备接收数据;有缓冲通道的容量大于 0,发送操作会在通道未满时立即返回,只有当通道已满时发送操作才会阻塞。
关闭通道: 发送方可以关闭通道,以表示没有更多的数据将被发送。接收方可以通过检查通道的关闭状态来确定是否还有更多的数据可接收。
当通道阻塞时,Go 运行时会将当前 goroutine 标记为阻塞状态,并将其放入等待队列中。当通道变为非阻塞状态时(例如有其他 goroutine 向通道发送数据),等待的 goroutine 将被重新唤醒,并继续执行。
通道的底层实现是使用环形队列(ring buffer)和互斥锁来实现的。当通道为空时,接收操作会阻塞等待,直到有数据被发送到通道;当通道已满时,发送操作会阻塞等待,直到有数据被接收。通过互斥锁来保护对通道数据的并发访问,确保多个 goroutine 可以安全地发送和接收数据。
关于go channel更多可见另外两篇文章深入理解 go chan和go chan 设计与实现
2 数据库知识
- 问题1:MySQL的事务隔离级别,可重复读是什么样的概念?(展盟,360)
| 隔离级别 | 英文 | 解释 |
|---|---|---|
| 读未提交 | Read Uncommited | 可以读取到为提交事务修改的数据 |
| 读已提交 | Read Commited | 只能读取到已经提交事务修改的数据 |
| 可重复读 | Read Repeatable | 可以重复读 |
| 可序列化 | Serializable | 并发的事务可转换成串行执行 |
可重复读是值在事务并发的时候,一个事务不会读到另外一个事务已经提交的数据,在事务执行期间能确保多次读到的数据是同一份,不会因为其他已提交的时候修改而变化。
mysql是通过MVCC来实现可重复读的
更多关于mysql事务可查看mysql事务隔离级别&MVCC
- 问题2:MySQL联合索引最左匹配原则(展盟)
MySQL 联合索引最左匹配原则指的是在使用联合索引时,如果查询条件涉及到了索引的多个列,MySQL 会尽可能地利用索引的最左前缀来进行匹配。具体来说,当使用联合索引时,MySQL 可以利用索引中的最左前缀来加速查询,但只有当查询条件涉及到索引的最左前缀时,索引才会被使用。
例如,假设有一个联合索引 (col1, col2, col3),如果查询条件中包含了 col1、col1 和 col1、col2,那么 MySQL 可以利用这个索引;但是如果查询条件中只包含了 col2 或 col3,那么这个索引就无法被利用。
这种最左匹配原则的设计是为了优化索引的使用。因为索引中的每一个列都会增加索引的大小,并且会带来额外的维护成本。因此,MySQL 会优先利用索引中的最左前缀来减少索引的大小,提高查询效率。
更多关于mysql索引可以查看mysql数据库索引结构及算法原理
- 问题3:MySQL的慢查询是怎么解决的?(展盟,360,小米)
使用索引优化查询: 索引是提高查询性能的关键。通过分析慢查询日志(slow query log)或者使用 MySQL 的性能分析工具(如 EXPLAIN)来确定慢查询的原因,然后针对性地创建合适的索引来优化查询。
优化 SQL 查询语句: 对查询语句进行优化可以显著提高查询性能。可以通过优化查询条件、避免使用全表扫描、减少不必要的字段查询等方式来优化 SQL 查询语句。
分析数据库设计: 数据库设计也会影响查询性能。合理的数据库设计包括选择合适的数据类型、避免过度范式化、合理设计表结构等,都可以提高查询性能。还包括分库分表、主从架构、存储引擎等优化。
调整数据库参数: 可以通过调整 MySQL 的配置参数来优化查询性能。例如,增大缓冲区大小、调整查询缓存大小、优化磁盘 I/O 等,都可以提高 MySQL 的性能。
升级硬件设备: 如果以上方法都无法解决慢查询问题,那么可能需要考虑升级硬件设备来提高数据库的处理能力。例如,增加内存、提升 CPU 性能、使用更快的存储设备等,都可以提高 MySQL 的性能。
使用缓存技术: 可以使用缓存技术(如 Memcached、Redis 等)来缓存查询结果,减少对数据库的访问压力,从而提高查询性能。
- 问题4:Redis遍历key的命令,可否用keys命令?(展盟)
KEYS 命令可以接受一个模式作为参数,并返回所有匹配该模式的键名。
例如,如果要遍历所有以 “user:” 开头的键名,可以使用如下命令:
KEYS user:*这将返回所有以 “user:” 开头的键名列表。
但是需要注意的是,KEYS 命令是一个高开销的操作,它会遍历整个数据库来查找匹配的键,这可能会导致性能问题,特别是在大型数据库中。因此,在生产环境中,应尽量避免使用 KEYS 命令,或者在非常必要时,限制其匹配范围,以减少对 Redis 服务器的负载。
另外,对于生产环境的应用,更好的方式是使用 Redis 的有序集合(Sorted Set)、哈希表(Hash)等数据结构来存储和管理数据,然后通过相应的命令来实现需要的功能,而不是依赖于 KEYS 命令。
- 问题5:MySQL的优化?(优咔科技)
合适的数据类型: 使用合适的数据类型可以减少存储空间的占用和查询的计算成本。尽量选择合适大小的数据类型,避免过度使用 VARCHAR、TEXT 等数据类型。
索引优化: 合理创建索引可以提高查询性能。需要根据查询频率和条件选择合适的列进行索引,并避免创建过多的索引。同时,定期检查并维护索引的健康状态,包括重建索引、删除不必要的索引等。
查询优化: 优化 SQL 查询语句可以减少查询的时间和资源消耗。通过分析查询执行计划(使用 EXPLAIN),避免全表扫描、避免使用 SELECT *、合理使用 JOIN 等方式来优化查询。
缓存优化: 使用缓存可以减少数据库的负载和提高查询性能。可以使用 MySQL 自带的查询缓存或者通过外部缓存(如 Memcached、Redis)来缓存查询结果。
参数调优: 调整 MySQL 的配置参数可以提高数据库的性能和稳定性。包括调整缓冲区大小、连接数、日志记录级别等参数。
分区表: 使用分区表可以提高查询性能和维护效率,特别是对于超大型数据库。将大表分割成多个小表,可以减少单表的数据量,提高查询效率。
定期清理: 定期清理数据库中的无用数据、过期数据和不必要的索引,可以提高数据库的性能和减少存储空间的占用。
备份和恢复策略: 建立合适的备份和恢复策略,保证数据库数据的安全和可靠性,以及快速恢复数据库的能力。
- 问题6:MonGoDB和MySQL的区别,MonGoDB的索引了解过么?(优咔科技)
数据模型:
- MySQL 是关系型数据库管理系统(RDBMS),基于表格的数据模型,数据以行和列的形式存储,支持 SQL 查询语言。
- MongoDB 是面向文档的 NoSQL 数据库管理系统,数据以文档的形式存储,文档是以 JSON/BSON 格式表示的键值对集合,不需要固定的结构,支持丰富的查询语言。
架构设计:
- MySQL 的架构是基于客户端-服务器模型,使用 SQL 语言进行数据操作。
- MongoDB 的架构是基于分布式的文档存储系统,数据以集群方式存储,支持自动数据分片和复制。
数据模型的灵活性:
- MySQL 的数据模型比较固定,需要事先定义好表的结构和字段类型。
- MongoDB 的数据模型比较灵活,不需要事先定义表结构,可以根据需要动态地添加新字段。
事务支持:
- MySQL 支持事务,具有 ACID 特性(原子性、一致性、隔离性、持久性)。
- MongoDB 在较新的版本中开始支持多文档事务,但并不是所有操作都支持事务,而且 MongoDB 的事务性能可能不如 MySQL。
索引和查询:
- MySQL 支持多种类型的索引,包括 B-Tree 索引、哈希索引等,支持复杂的 SQL 查询语句。mysql索引可查看Mysql面试题
- MongoDB 支持各种类型的索引,包括单字段索引、复合索引、全文索引等,同时支持丰富的查询操作符和聚合操作。
- 问题7:Redis的数据类型?(优咔科技,360)
redis有9种基本数据结构,string,list,hash,set,zset,bitmap,GeoHash,HyperLogLog,Streams。常见的是前面五种。
字符串(String): 字符串是 Redis 中最基本的数据类型,可以存储任意类型的数据,包括文本、数字、二进制数据等。字符串类型的值最大可以存储 512 MB 的数据。列表(List): 列表是一种有序的、可重复的数据结构,它可以存储多个元素,每个元素都有一个索引值。列表类型的值最大可以存储 2^32 - 1 个元素。
哈希表(Hash): 哈希表是一种键值对存储结构,用于存储多个字段和对应的值。哈希表类型的值可以存储 2^32 - 1 个字段和值对。
集合(Set): 集合是一种无序的、不重复的数据结构,它可以存储多个元素,每个元素都是唯一的。集合类型的值最大可以存储 2^32 - 1 个元素。
有序集合(Sorted Set): 有序集合是一种有序的、不重复的数据结构,它可以存储多个元素,并且每个元素都有一个分数值,根据分数值进行排序。有序集合类型的值最大可以存储 2^32 - 1 个元素。
- 问题8:Redis持久化的方式(优咔科技)
RDB(Redis DataBase)持久化: RDB 持久化通过将 Redis 在内存中的数据快照(snapshot)写入到磁盘上的 RDB 文件中来实现。RDB 持久化是将 Redis 在某个时间点的数据状态保存到磁盘上,可以使用 SAVE 或 BGSAVE 命令手动触发快照的生成,也可以通过配置文件中的 save 指令设置自动触发快照的条件。RDB 持久化适用于备份和灾难恢复等场景,因为它可以生成整个数据集的快照,并将其保存到磁盘上,但是它不适合对数据进行实时备份和恢复,因为生成快照可能会造成短暂的阻塞。
AOF(Append Only File)持久化: AOF 持久化通过将 Redis 执行的写命令以追加(append)的方式写入到一个文件中来实现。AOF 文件保存了 Redis 服务器接收到的所有写命令,以文本格式保存,因此可以非常容易地阅读和分析。AOF 持久化有三种不同的同步策略:always、everysec 和 no,可以在配置文件中进行设置。AOF 持久化适用于对数据进行实时备份和恢复,因为它可以将 Redis 执行的每一条写命令都保存下来,可以保证数据不丢失。
更多可见Redis持久化策略
- 问题9:MySQL的索引,聚簇索引和非聚簇索引的区别?索引是用什么实现的(b+ tree)?(360)
聚簇索引和非聚簇索是基于物理存储的角度区分索引的
聚簇索引(Clustered Index):
聚簇索引是一种将数据存储和索引存储在一起的索引结构。
在聚簇索引中,数据行的物理顺序与索引的逻辑顺序是一致的,即索引的键值会直接指向数据行。
InnoDB 存储引擎中的主键索引就是一种聚簇索引,如果没有显式指定主键,则会使用一个称为 ROWID 的隐藏字段作为主键。
由于数据行的物理顺序与索引的逻辑顺序一致,因此聚簇索引能够提供较快的数据访问速度,特别是在范围查询时。非聚簇索引(Non-Clustered Index):
非聚簇索引是一种将索引与数据分开存储的索引结构。
在非聚簇索引中,索引存储了指向数据行的指针(例如,主键或 ROWID)而不是数据行本身。
由于数据和索引是分开存储的,因此对于使用非聚簇索引的查询,需要先根据索引查找到对应的数据行指针,然后再根据指针找到数据行,因此查询的性能相对较低。
mysql索引通常是使用树结构来实现的,其中最常见的索引实现是 B-树(B-Tree)和 B+ 树(B-Tree)。这些树结构可以快速地定位到数据,以提高查询的效率。
B-树(B-Tree):
B-树是一种平衡的树结构,它能够在树的所有叶子节点之间保持相同的深度。
在 B-树 中,每个节点都可以包含多个键值对,其中键值对按键的顺序排列。内部节点包含键和指向子节点的指针,叶子节点包含键和指向实际数据的指针。
B-树通常用于磁盘存储上的索引,因为它对于范围查询和磁盘访问效率较高。B+ 树(B+ Tree):
B+ 树是 B-树 的一种变种,它与 B-树类似,但有一些不同之处。
在 B+ 树 中,所有的数据都存储在叶子节点中,而内部节点只存储键和指向子节点的指针。
B+ 树的叶子节点之间使用链表连接起来,这样可以很容易地进行范围查询。
B+ 树通常用于内存存储上的索引,因为它对于范围查询和内存访问效率较高。
关于mysql索引可查看mysql数据库索引结构及算法原理
- 问题10:MySQL事务隔离级别(RU/RC/RR/S),可重复读是怎么实现的?幻读是怎么解决的?(360)
事务隔离级别和可重复的见问题1
幻读是通过可串行化解决的。这是最严格的隔离级别,保证了事务之间的完全隔离,不会出现任何并发问题,包括幻读。但是由于它的严格性,可能会导致并发性能下降。
关于mysql事务可查看mysql事务隔离级别&MVCC
- 问题11:Redis ZSet底层是怎么实现的(压缩链表、跳表)(360)
zset内部有2种编码实现
ziplist(压缩列表):当有序集合内元素个数小于等于zset-max-ziplist-entries(默认128个),并且每个元素的值都小于zset-max-ziplist-value(默认64字节)。redis会使用ziplist作为集合内部实现,可以减少内存的使用。
skiplist(跳表):当有序集合不满足ziplist作为内部实现时,使用skiplist作为内部实现,因为此时ziplist的读写效率会有降低
更多关于redis数据结构可查看redis五种基本数据结构及其编码方式(全且精)
3 kafka
- 问题1:kafka同步租户时如何防止信息丢失(事务:commit、autocommit)(展盟)
在 Kafka 中,同步副本(replicas)之间的数据一致性是由 ISR(In-Sync Replicas)机制来保证的。ISR 是指那些能够保持和 Leader 副本(leader replica)保持同步的副本。当生产者发送消息到 Kafka 集群时,只有 ISR 中的副本才会被写入消息,并且只有在 ISR 中的副本都成功写入消息后,生产者才会收到确认。这样可以确保在发生故障切换时,新的 Leader 副本能够有足够的数据来保持数据的一致性。
但是,即使使用 ISR 机制也不能完全杜绝消息丢失的情况。在某些极端情况下,仍然可能出现消息丢失的情况,比如:
ISR 中的所有副本同时发生故障: 如果 ISR 中的所有副本同时发生故障,那么生产者发送的消息就可能会丢失。
消息被 ACK 但尚未写入到所有 ISR 中: 如果生产者收到了消息的 ACK,但消息尚未写入到所有 ISR 中,而此时发生了 Leader 副本故障,那么消息就可能会丢失。
为了防止这种情况的发生,可以采取以下几种策略:
设置合适的副本数和 ISR 数: 设置足够多的副本数和 ISR 数,以确保即使发生一些副本故障,仍然能够保持数据的一致性。
使用同步副本ACK机制: 在生产者发送消息时,使用同步副本ACK机制(acks=all),确保消息被写入到所有 ISR 中后才返回确认。
使用消息日志和监控系统: 使用消息日志和监控系统来记录消息的发送和确认情况,及时发现可能导致消息丢失的问题,并进行处理。
定期备份数据: 定期备份数据到外部存储,以防止发生数据丢失的情况。
通过以上方式,可以降低 Kafka 中消息丢失的风险,并确保数据的一致性和可靠性。
4 Kubernetes相关知识
- 问题1:介绍istio相关概念(展盟,优咔科技,360)
Istio 是一个开源的服务网格(Service Mesh)解决方案,旨在解决微服务架构中的通信、安全、控制和观察等方面的问题。以下是 Istio 中一些重要的概念:
服务网格(Service Mesh):
- 服务网格是一种为微服务架构提供的基础设施层,用于管理服务间的通信、安全性、流量控制和观测等方面的需求。
- Istio 使用 Envoy 作为代理(Sidecar)部署在每个服务实例旁边,构成了一个分布式的服务网格。
代理(Sidecar):
- 代理是 Istio 中的一个核心概念,它是一个独立的网络代理容器,与应用程序容器共同部署在同一个 Pod 中。
- 代理通过拦截进出 Pod 的流量,并与 Istio 控制平面协同工作,实现流量管理、安全增强、监控和追踪等功能。
流量管理(Traffic Management):
- Istio 提供了丰富的流量管理功能,包括流量路由、负载均衡、故障注入、熔断和限流等。
- 使用 Istio 可以通过简单的配置来控制流量的路由和分发,实现 A/B 测试、灰度发布等功能。
安全增强(Security):
- Istio 提供了服务间的安全增强功能,包括身份认证、访问控制、流量加密和审计等。
- 使用 Istio 可以通过策略来定义哪些服务可以相互通信,以及如何加密和保护通信的数据。
监控和追踪(Observability):
- Istio 提供了丰富的监控和追踪功能,可以实时查看服务的性能指标、请求流量、错误率和延迟等。
- 使用 Istio 可以集成各种监控系统和追踪工具,帮助用户更好地理解和调试微服务架构。
控制平面(Control Plane):
- Istio 的控制平面包括 Pilot、Mixer、Citadel 和 Galley 等组件,用于管理和配置服务网格中的代理和策略。
- 控制平面负责处理流量管理、安全增强、策略配置和监控等方面的功能,与数据平面(即运行在每个服务实例中的 Envoy 代理)协同工作。
这些概念组成了 Istio 的核心特性,使其成为一个强大的微服务架构的解决方案,能够帮助用户更好地构建、管理和运行微服务应用。
- 问题2:k8s的service,集群用的什么网络插件(calico、flannel)?(展盟)
Kubernetes(K8s)的 Service 是一种抽象,用于定义一组 Pod 实例的访问方式。在 Kubernetes 集群中,Service 通过标签选择器(label selector)来关联一组 Pod,提供了统一的访问入口,从而可以实现负载均衡、服务发现和服务间通信等功能。
至于 Kubernetes 集群中使用的网络插件,则是用于实现 Pod 之间的网络通信,以及 Service 与 Pod 之间的通信。常见的 Kubernetes 网络插件包括:
Flannel: Flannel 是一个简单而高效的网络插件,它通过在每个节点上创建一个虚拟网络(VXLAN 或者 UDP),实现了 Pod 之间的网络通信,并通过 iptables 规则实现了 Service 的负载均衡功能。
Calico: Calico 是一个功能强大的网络插件,它使用了 BGP 协议来动态路由 Pod 的流量,实现了高效的网络通信和跨节点的负载均衡功能。Calico 还提供了丰富的网络策略功能,可以实现精细的网络安全控制。
Cilium: Cilium 是一个基于 eBPF(Extended Berkeley Packet Filter)的网络插件,它利用 Linux 内核的功能来实现高性能的网络转发和安全控制。Cilium 支持网络层和应用层的负载均衡,以及丰富的网络策略和安全功能。
Kube-router: Kube-router 是一个全功能的网络插件,它支持基于 VXLAN 和 BGP 的网络通信,以及各种网络策略和负载均衡功能。Kube-router 还支持 IPv6 和 IPVS 等高级功能。
Weave Net: Weave Net 是一个易于部署和使用的网络插件,它提供了简单的网络拓扑和通信模型,支持基于 UDP 和 VXLAN 的网络通信,以及负载均衡和网络策略功能。
这些网络插件都可以与 Kubernetes 集群配合使用,实现 Pod 之间的网络通信和 Service 的负载均衡功能。选择合适的网络插件取决于集群的需求和环境,需要考虑网络性能、安全性、可扩展性和易用性等方面的因素。
- 问题3:聊聊云原生是什么?(优咔科技)
以下是云原生的核心概念和特点:云原生(Cloud Native)是一种软件架构和开发模式,旨在利用云计算平台和容器技术,构建可扩展、可靠和高效的应用程序。云原生应用程序通常以微服务架构设计,并利用容器化、自动化部署、动态扩展、服务网格、持续交付等技术实践,以便更快地交付业务价值,适应快速变化的市场需求。
容器化(Containerization): 云原生应用程序通常使用容器技术(如 Docker)将应用程序及其依赖项打包为轻量级的容器镜像。容器提供了隔离性、可移植性和可部署性,使应用程序能够在不同环境中一致地运行。
微服务架构(Microservices): 云原生应用程序通常以微服务架构设计,将复杂的单体应用程序拆分为多个独立的服务,每个服务专注于特定的业务功能,通过 API 或消息队列进行通信。
自动化部署(Continuous Deployment): 云原生应用程序借助自动化部署工具(如 Kubernetes、Helm、Jenkins 等)实现持续交付和部署。通过自动化流水线,开发团队能够快速、可靠地将代码更新部署到生产环境中。
弹性伸缩(Elastic Scalability): 云原生应用程序能够根据流量和负载自动扩展或收缩,以满足不同的需求。通过容器编排平台(如 Kubernetes)和自动化扩展机制,可以实现弹性伸缩和资源利用率的最大化。
服务网格(Service Mesh): 云原生应用程序通常使用服务网格来管理和控制服务之间的通信。服务网格提供了可观测性、安全性、流量控制和故障恢复等功能,使得服务间通信更加可靠和安全。
云原生治理(Cloud Native Governance): 云原生应用程序采用分布式架构,需要具备相应的治理机制来确保安全性、可靠性和合规性。云原生治理包括安全审计、监控告警、访问控制、故障注入等方面的实践。
总的来说,云原生是一种以云计算平台和容器技术为基础的新型应用程序开发和运行模式,旨在提高应用程序的可靠性、可伸缩性和敏捷性,以适应快速变化的市场需求。通过采用云原生架构和实践,企业可以更快地交付价值、更好地适应变化,并提高竞争力。
- 问题4:常见的容器运行时(优咔科技)
Docker Containerd: Docker Containerd 是 Docker 容器运行时的核心组件之一,负责管理容器的生命周期、镜像管理和容器执行。
containerd: containerd 是一个开源的容器运行时,是 Docker 引擎的核心组件之一。containerd 提供了容器的生命周期管理、镜像管理、容器执行等基本功能。
CRI-O: CRI-O 是一个专门为 Kubernetes 设计的容器运行时,它符合 Kubernetes Container Runtime Interface(CRI)规范,提供了容器生命周期管理、镜像管理等功能。
containerd-shim: containerd-shim 是 containerd 的一个子组件,用于将 containerd 与 OCI(Open Container Initiative)兼容的容器运行时(如 runc)集成在一起,实现容器的创建和执行。
runc: runc 是一个符合 OCI 标准的轻量级容器运行时,负责解析容器镜像、创建容器进程、设置容器的文件系统和网络环境等。
这些容器运行时可以根据需要选择和配置,用于在容器平台上执行和管理容器。它们提供了一致的容器管理接口,使得容器可以在不同的环境中轻松迁移和运行。
- 问题5:数据库是如何部署的(k8s的statefulset)(优咔科技)
在 Kubernetes 中部署数据库通常使用 StatefulSet 这个控制器,StatefulSet 是用于部署有状态应用程序的控制器,如数据库、消息队列等。与 Deployment 不同,StatefulSet 会给每个 Pod 分配一个唯一的标识符(通常是索引),并确保这些标识符在 Pod 重新调度、扩容或缩容时保持不变。这样做的目的是为了确保有状态应用程序在重新启动后能够保持持久化存储和网络标识的一致性。
下面是部署数据库(例如 MySQL、PostgreSQL)的一般步骤:
创建持久化存储卷: 首先,你需要创建持久化存储卷(PersistentVolume,简称 PV)或者使用动态存储卷(Dynamic Provisioning),以便数据库能够持久化地存储数据。你可以使用 Kubernetes 的 PersistentVolumeClaim(PVC)来声明对持久化存储的需求。
创建 StatefulSet: 接下来,你需要创建一个 StatefulSet 对象,并指定数据库镜像、存储卷模板、环境变量等配置信息。在 StatefulSet 中,你可以定义数据库 Pod 的副本数、网络策略、持久化存储的挂载方式等。
创建 Headless Service: StatefulSet 中的每个 Pod 都有一个唯一的网络标识符,但没有固定的 IP 地址。为了让其他应用程序能够通过 DNS 解析访问到这些 Pod,你需要创建一个 Headless Service。Headless Service 会为 StatefulSet 中的每个 Pod 分配一个 DNS 记录,通过该 DNS 记录可以访问到 Pod。
部署配置和密钥: 如果数据库需要使用配置文件或者密码,你可以通过 Kubernetes 的 ConfigMap 和 Secret 来存储这些配置信息,并在 StatefulSet 中进行挂载和使用。
应用部署: 部署 StatefulSet 后,Kubernetes 会自动创建和管理数据库 Pod,并根据需要进行扩容和缩容。你可以使用 kubectl 命令行工具来查看数据库 Pod 的状态和日志。
通过上述步骤,你可以在 Kubernetes 中部署数据库,并确保数据库的持久化存储、网络标识和扩缩容等功能。这样的部署方式使得数据库能够在容器化环境中具备高可用性、可伸缩性和易管理性。
- 问题6:介绍k8s master的组件(优咔科技)
ubernetes 的 Master 组件是集群的控制平面,负责管理集群的状态、调度应用程序、处理集群事件和监控集群健康状态等。
Master 组件包括以下核心组件:
kube-apiserver(API Server):
- kube-apiserver 是 Kubernetes 的 API 服务端,提供了集群内各种资源的 CRUD 操作接口,包括 Pod、Service、Namespace 等。
- 所有的管理操作都通过 kube-apiserver 提供的 API 来进行,客户端和其他组件通过 HTTP 或 gRPC 协议与 kube-apiserver 进行通信。
etcd:
etcd 是一个分布式键值存储系统,用于存储 Kubernetes 集群的状态信息、配置数据和元数据等。
kube-apiserver 和其他组件通过 etcd 进行数据交互,etcd 提供了高可用性和一致性保证,确保了集群的稳定性和可靠性。
kube-scheduler(Scheduler):
kube-scheduler 是 Kubernetes 的调度器,负责根据 Pod 的调度需求和集群资源情况,将 Pod 分配到合适的节点上运行。
kube-scheduler 根据调度策略和优先级对 Pod 进行调度,包括节点资源利用率、亲和性和亲和性等。
kube-controller-manager(Controller Manager):
- kube-controller-manager 包含了多个控制器,负责监控集群的状态、控制器的运行和控制资源的自动化操作。
- 典型的控制器包括 ReplicaSet 控制器、Deployment 控制器、Service 控制器等,它们负责管理集群中的各种资源对象,并确保其达到预期的状态。
cloud-controller-manager:
- cloud-controller-manager 是一个可选的组件,用于集成云服务提供商的特定功能,如自动扩展、负载均衡等。
- cloud-controller-manager 包含了与云服务提供商相关的控制器,如 Node 控制器、路由控制器等。
这些 Master 组件共同工作,构成了 Kubernetes 的控制平面,负责管理集群的状态、调度应用程序、处理集群事件和监控集群健康状态等。通过这些组件,用户可以方便地管理和运行容器化的应用程序,实现高可用性、可伸缩性和自动化运维。
- 问题7:容器和虚机的不同点?(优咔科技)
资源隔离:
- 虚拟机:每个虚拟机都有自己的操作系统内核和完整的虚拟硬件,虚拟机之间的资源是完全隔离的,包括 CPU、内存、磁盘和网络等。
- 容器:容器共享宿主机的操作系统内核,因此容器之间的资源隔离程度较低。虽然容器可以限制对资源的访问,但它们共享相同的操作系统和硬件资源。
启动时间和资源消耗:
- 虚拟机:启动虚拟机需要较长的时间,通常需要几分钟来启动一个虚拟机,并且会消耗较多的资源。
- 容器:容器启动速度快,通常只需要几秒钟就可以启动一个容器,并且消耗的资源较少,因为容器共享宿主机的内核和其他系统资源。
部署和管理:
- 虚拟机:管理虚拟机通常需要额外的虚拟化管理软件(如 VMware、VirtualBox、KVM 等),以及操作系统和应用程序的管理。
- 容器:容器可以使用容器编排平台(如 Kubernetes、Docker Swarm 等)来管理和部署,这些平台提供了自动化部署、扩缩容、服务发现和健康检查等功能,简化了应用程序的管理和维护。
性能:
- 虚拟机:由于每个虚拟机都有自己的操作系统内核和虚拟硬件,因此虚拟机之间的性能隔离较好,但可能会因为虚拟化的开销而导致性能下降。
- 容器:容器之间共享宿主机的操作系统内核和硬件资源,因此容器的性能较虚拟机更高,但缺少了虚拟机的完全隔离性。
综上所述,虚拟机和容器在资源隔离、启动时间和资源消耗、部署和管理、性能等方面有所不同,各有优劣。选择使用虚拟机还是容器取决于具体的场景和需求,以及对资源隔离、性能、部署和管理的要求。
- 问题8:k8s的源码看过么?(360)
- 问题9:k8s创建一个Pod的全过程(小米)
创建一个 Pod 的全过程涉及到多个步骤,包括定义 Pod 的 YAML 文件、提交 Pod 到 Kubernetes 集群、API Server 的处理和调度器的调度等。
以下是创建一个 Pod 的典型过程:
定义 Pod 的 YAML 文件:
- 首先,你需要编写一个 Pod 的 YAML 文件,指定 Pod 的元数据(如名称、命名空间)、容器的镜像、端口、环境变量、卷挂载等配置信息。
提交 Pod 到 Kubernetes 集群:
- 使用 kubectl 工具或者 Kubernetes 的 API 接口,将 Pod 的 YAML 文件提交到 Kubernetes 集群中。
- kubectl 工具会将 Pod 的 YAML 文件发送给 Kubernetes 的 API Server,API Server 将会对其进行处理。
API Server 的处理:
- 当 Pod 的 YAML 文件被提交到 Kubernetes 集群中时,API Server 会接收到请求,并根据请求的内容进行处理。
- API Server 会验证 Pod 的配置信息是否符合规范,如是否指定了必需的字段、是否有权限创建 Pod 等。
调度器的调度:
- 一旦 Pod 的配置信息通过了 API Server 的验证,API Server 将把 Pod 分配给调度器进行调度。
- 调度器会根据 Pod 的调度要求和集群资源情况,选择合适的节点将 Pod 部署到其中。
节点的创建和调度:
- 调度器选择合适的节点后,Kubernetes 将在该节点上创建一个 Pod 所需的容器和其他资源。
- kubelet 代理在节点上接收到调度请求后,会下载指定的容器镜像并创建容器实例。
容器的启动和运行:
- 一旦容器创建成功,kubelet 代理会启动容器并将其加入到 Pod 的网络命名空间中。
- 容器启动后,它会根据定义在 Pod YAML 文件中的配置信息来运行应用程序,并监听来自集群内部和外部的网络请求。
通过以上步骤,一个 Pod 就成功地被创建和部署到了 Kubernetes 集群中,并且开始运行其中定义的容器应用程序。整个过程是自动化的,由 Kubernetes 控制平面和节点代理共同协作完成。
- 问题10:client-Go Informer机制全过程?(小米)
Client-go 是 Kubernetes 官方提供的 Go 语言客户端库,用于与 Kubernetes API 进行交互。Informer 机制是 client-go 中用于实现客户端缓存和事件监听的重要组件。
下面是 client-go Informer 机制的全过程:
创建客户端: 首先,你需要使用 client-go 创建一个 Kubernetes 客户端,用于与 Kubernetes API 进行通信。客户端可以通过直接连接到 Kubernetes API Server 或者使用 InClusterConfig 或 OutOfClusterConfig 方法来获取 Kubernetes 集群的配置信息。
创建 SharedInformerFactory: 在创建客户端之后,你需要使用 SharedInformerFactory 创建一个 SharedInformerFactory 对象。SharedInformerFactory 是用于创建和管理 Informer 对象的工厂类,每个 SharedInformerFactory 对象都维护了一组 Informer 对象。
创建 Informer 对象: 使用 SharedInformerFactory 创建一个或多个 Informer 对象,每个 Informer 对象对应一个 Kubernetes 资源类型(如 Pod、Service、Deployment 等)。Informer 对象会向 Kubernetes API Server 发送 ListWatch 请求,获取资源列表并监视资源变更事件。
注册事件处理函数: 在创建 Informer 对象之后,你需要注册事件处理函数,用于处理资源的增删改事件。事件处理函数可以通过 AddEventHandler 方法来注册,通常包括对资源的增删改操作。
启动 Informer: 在注册事件处理函数之后,你需要调用 Informer 对象的 Run 方法来启动 Informer。Run 方法会启动 Informer 的事件循环,不断地监听和处理资源变更事件,并调用注册的事件处理函数。
处理事件: 当 Kubernetes 中的资源发生变更时,Informer 会收到相应的事件通知,并调用注册的事件处理函数来处理事件。事件处理函数通常会更新客户端的缓存,以反映最新的资源状态。
通过以上步骤,你可以使用 client-go 的 Informer 机制来实现对 Kubernetes 资源的监视和事件处理。Informer 机制可以帮助你编写高效、可靠的 Kubernetes 客户端应用程序,实现对 Kubernetes 资源的实时监控和响应。
- 问题11:Delta-FIFO和普通队列的区别?Store是什么?Reflector是什么?(小米)
Delta-FIFO和普通队列的区别Delta-FIFO(First-In-First-Out)队列是 Kubernetes 中一种特殊的队列实现,用于在资源控制器(如 Deployment、StatefulSet 等)中管理对象的更新事件。
与普通队列相比,Delta-FIFO 队列有以下几点不同之处:
记录变化: Delta-FIFO 队列不仅存储对象的当前状态,还会记录对象的变化(Delta)。每次修改对象时,Delta-FIFO 队列都会存储该对象的变化,并在需要时提供完整的对象状态。
乐观并发控制: Delta-FIFO 队列使用乐观并发控制策略来处理资源的更新。当多个线程同时修改同一个对象时,Delta-FIFO 队列会根据对象的版本号(ResourceVersion)来检测冲突,并且只接受最新的更新。
资源版本号: 每个对象在 Delta-FIFO 队列中都有一个唯一的资源版本号。当对象被修改时,资源版本号会递增,用于检测对象的变化和冲突。
事件处理: Delta-FIFO 队列会根据对象的变化生成对应的事件(Add、Update、Delete),并将事件发送给注册的监听器。控制器可以根据这些事件来更新内部状态和执行相应的操作。
去重处理: Delta-FIFO 队列会对重复的事件进行去重处理,以确保每个事件只被处理一次。这样可以避免重复处理相同的更新操作,提高系统的效率和可靠性。
Store
Store 是一个本地缓存,用于存储 Kubernetes 资源对象的状态信息。它通常是一个类似于 Map 的数据结构,以资源的 UID 作为键,存储资源对象的副本。
Store 可以被多个组件共享和访问,用于提供对 Kubernetes 资源对象的快速访问和查询。例如,控制器可以使用 Store 来获取资源的当前状态,而不必每次都向 Kubernetes API Server 发送请求。
Store 还提供了对资源对象的增删改查等基本操作,以及针对多个资源对象的批量操作。
Reflector
Reflector 是一个用于监视 Kubernetes 资源对象变更事件的组件。它会定期向 Kubernetes API Server 发送 ListWatch 请求,获取最新的资源列表,并监听资源变更事件。
当 Reflector 接收到资源对象的增删改事件时,它会更新 Store 中对应资源对象的状态,以反映最新的状态。这样,控制器可以通过访问 Store 来获取最新的资源状态,而无需自己监听事件和维护状态。
Reflector 还提供了一些可配置的参数,如同步周期、资源类型、字段选择器等,以便用户根据需要对监视行为进行定制。
总的来说,Store 是一个本地缓存,用于存储 Kubernetes 资源对象的状态信息,而 Reflector 是一个用于监视资源变更事件的组件,负责更新 Store 中的状态以反映最新的变化。通过 Store 和 Reflector,Kubernetes 控制器可以实现高效的资源监视和状态管理。
- 问题12:k8s官方sample-controller和kubebuilder生成controller有什么区别?(小米)
sample-controller 和 kubebuilder 是两种不同的工具或方法,用于创建 Kubernetes 控制器。
它们之间的区别主要体现在以下几个方面:
生成方式:
- sample-controller 是一个官方示例,是手动编写的一个简单的控制器,用于演示如何使用 client-go 来编写自定义控制器。你需要手动编写代码,并且需要理解控制器的核心逻辑和原理。
- kubebuilder 是一个专门用于快速生成和构建 Kubernetes 控制器的工具,它提供了命令行工具和代码生成器,可以自动生成控制器的框架代码和基本结构。你只需要定义资源的 API 规范,kubebuilder 就会根据规范自动生成控制器的代码,并且提供了一些默认实现和最佳实践。
功能和特性:
- sample-controller 是一个简单的示例,只实现了基本的控制器功能,如监听资源变更事件、处理事件、同步资源状态等。它的功能比较有限,适合用于学习和理解控制器的基本原理。
- kubebuilder 提供了更丰富和完整的功能和特性,包括自动生成代码、声明式 API 定义、CRD(Custom Resource Definition)支持、Webhook 支持、单元测试、文档生成等。使用 kubebuilder 可以更快地构建高质量和可扩展的自定义控制器。
生态和社区支持:
- sample-controller 是 Kubernetes 官方提供的一个示例,属于 Kubernetes 社区的一部分。它的代码比较简单,适合用于学习和实践,但在生产环境中可能需要更多的功能和扩展。
- kubebuilder 是由社区维护的一个开源项目,得到了广泛的支持和贡献。它提供了丰富的文档、示例和教程,以及活跃的社区讨论和技术支持。使用 kubebuilder 可以更容易地构建和维护符合最佳实践的控制器应用程序。
总的来说,sample-controller 是一个简单的示例,适合用于学习和理解控制器的基本原理,而 kubebuilder 则是一个更强大和完整的工具,用于快速生成和构建符合最佳实践的 Kubernetes 控制器应用程序。
5 服务治理与微服务架构
问题1:kitex框架:服务治理(负载均衡、服务降级…)、可观测(链路追踪…)(展盟)
问题2:istio是做数据面还是控制面?(优咔科技)
问题3:Istio负载均衡的策略(优咔科技)
问题4:Service mesh中南北向和东西向流量处理?(优咔科技)
问题5:Linux命令和系统知识
基本命令:
- 文件和目录操作:ls、cd、pwd、mkdir、rm、cp、mv 等。
- 文件内容查看和编辑:cat、less、head、tail、vi、nano 等。
- 文件权限管理:chmod、chown、chgrp 等。
- 进程管理:ps、top、kill、killall、nice 等。
- 用户和组管理:useradd、usermod、userdel、groupadd、groupmod、groupdel 等。
- 网络操作:ifconfig、ping、netstat、traceroute、ssh、scp、wget 等。
文件系统和磁盘管理:
- 文件系统类型和挂载:df、du、mount、umount 等。
- 文件系统检查和修复:fsck、e2fsck 等。
- 磁盘分区和格式化:fdisk、mkfs、mkswap 等。
系统管理和配置:
- 系统信息查看:uname、hostname、uptime、date 等。
- 系统服务管理:systemctl、service 等。
- 日志查看:dmesg、journalctl、tail -f /var/log/messages 等。
- 系统配置文件编辑:/etc 目录下的各种配置文件,如/etc/fstab、/etc/hosts、/etc/resolv.conf 等。
用户和权限管理:
- 用户和组管理:useradd、usermod、userdel、groupadd、groupmod、groupdel 等。
- 权限设置:chmod、chown、chgrp 等。
网络和通信:
- 网络配置和信息查看:ifconfig、ip、route、netstat、ss 等。
- 网络连接和通信工具:ping、traceroute、telnet、ssh、nc、curl、wget 等。
问题6:Linux的awk、strace命令(展盟)
awk- awk 是一种文本处理工具,用于从文件或标准输入中提取数据并进行处理。它通常用于对结构化文本进行分析、过滤、格式化和报告。
- awk 的基本语法是 awk ‘pattern {action}’ file,其中 pattern 是匹配条件,action 是对匹配行执行的操作。例如,awk ‘{print $1}’ file.txt 可以打印文件 file.txt 中每行的第一个字段。
- awk 还支持在命令行中定义变量、函数和条件判断等高级特性,因此它在文本处理和数据分析中非常灵活和强大。
strace
- strace 是一个系统调用跟踪工具,用于监视程序的系统调用和信号。它可以跟踪程序执行期间发生的系统调用,并打印系统调用的参数、返回值和耗时等信息。
- strace 的基本用法是 strace command [arguments],其中 command 是要跟踪的程序,arguments 是程序的参数。例如,strace ls -l 可以跟踪 ls -l 命令执行期间发生的系统调用。
- strace 可以帮助开发人员调试程序,了解程序与操作系统之间的交互过程,识别性能瓶颈和异常行为,从而更好地优化程序和解决问题。
总的来说,awk 用于文本处理和数据分析,而 strace 用于系统调用跟踪和程序调试,它们都是 Linux 中非常实用的工具。
问题7:linux根据服务名称查看端口号(netstat -tunlp | grep 服务名称)(柯莱特-外派小红书)
sudo netstat -tuln | grep "服务名称"问题8:linux根据服务名称查看pid(ps -aux | 服务名称)(柯莱特-外派小红书)
sudo systemctl status 服务名称这个命令会显示指定服务的状态信息,其中包括该服务的 PID。你可以从输出中找到对应的 PID。
问题9:linux进程间通信的方式(socket、管道…..)(柯莱特-外派小红书)
管道(Pipe): 管道是一种半双工的通信方式,用于在父进程和子进程之间进行通信。管道可以通过 pipe 系统调用创建,也可以通过 | 操作符在 Shell 中创建。管道分为匿名管道和命名管道两种形式。
命名管道(Named Pipe): 命名管道也是一种半双工的通信方式,不同于管道的是,命名管道允许在文件系统中创建一个特殊文件作为通信通道,进程可以通过该文件进行通信。命名管道通过 mkfifo 命令创建。
消息队列(Message Queue): 消息队列是一种通过内核维护的消息缓冲区进行通信的方式,进程可以向消息队列中发送消息,也可以从中接收消息。消息队列通常采用先进先出(FIFO)的方式进行消息传递。
信号(Signal): 信号是一种异步的通信方式,用于向进程发送通知或中断信号。进程可以通过 kill 命令发送信号,也可以通过系统调用注册信号处理函数来处理接收到的信号。
共享内存(Shared Memory): 共享内存是一种高效的进程间通信方式,允许多个进程共享同一块内存区域,从而实现数据的快速交换。进程可以通过 shmget 系统调用获取共享内存段,然后通过 shmat 系统调用将共享内存映射到自己的地址空间中。
信号量(Semaphore): 信号量是一种用于控制进程对共享资源的访问的机制,可以用来解决进程同步和互斥的问题。进程可以通过 semget 系统调用获取信号量集合,然后通过 semop 系统调用对信号量进行操作。
套接字(Socket): 套接字是一种进程间通信的标准方法,可以在不同主机上的进程之间进行通信。套接字通常用于网络编程,但也可以用于本地进程间通信(Unix 域套接字)。
6 docker
- 问题1:docker构建镜像,推送到镜像仓库(柯莱特-外派小红书)
1.编写 Dockerfile: 首先,你需要编写一个 Dockerfile 文件,定义了如何构建你的 Docker 镜像。Dockerfile 包含了一系列的指令,用于设置镜像的环境和内容。
2.构建镜像: 在 Dockerfile 所在的目录下,使用 docker build 命令来构建镜像。例如:
docker build -t 镜像名称:版本号 .3.登录到镜像仓库: 使用 docker login 命令登录到你的镜像仓库,例如 Docker Hub:
docker login4.标记镜像: 使用 docker tag 命令为你的镜像打上标签,指定要推送到的镜像仓库地址和版本号。例如:
docker tag 镜像名称:版本号 镜像仓库地址/镜像名称:版本号5.推送镜像: 使用 docker push 命令将镜像推送到镜像仓库。例如:
docker push 镜像仓库地址/镜像名称:版本号完成以上步骤后,你的 Docker 镜像就会被构建并推送到镜像仓库中,其他用户就可以通过镜像仓库地址来获取和使用这个镜像了。
7 监控和度量
- 问题1:Promethues在项目中的应用(柯莱特-外派小红书,小米,360)
Prometheus 是一款开源的监控和警报工具,它最初由 SoundCloud 开发,后来捐赠给了云原生计算基金会(CNCF)。Prometheus 主要用于收集、存储和查询应用程序和系统的监控指标,同时还支持基于规则的警报和自动化任务。
在项目中,Prometheus 可以应用于以下方面:
监控应用程序和系统指标: Prometheus 可以轻松地收集应用程序和系统的各种指标,如 CPU 使用率、内存使用率、网络流量、磁盘 I/O 等。通过监控这些指标,你可以了解应用程序和系统的运行状况,并及时发现潜在的问题。
自定义指标采集: Prometheus 支持自定义指标采集,你可以通过在应用程序中埋点的方式,将自定义的指标发送给 Prometheus。这样,你就可以监控应用程序的业务指标,如请求数、响应时间、错误率等。
警报和告警: Prometheus 支持基于规则的警报和告警功能,你可以定义警报规则,并设置触发条件和告警通知方式。当监控指标达到或超过设定的阈值时,Prometheus 将触发警报,并通过邮件、短信等方式通知相关人员。
数据可视化: Prometheus 提供了丰富的查询语言和图形化界面,你可以使用 PromQL 查询语言来查询和分析监控数据,并通过 Grafana 等数据可视化工具将监控数据可视化,生成各种图表和仪表盘,帮助你更直观地了解应用程序和系统的运行情况。
自动化运维: Prometheus 还支持自动化运维任务,如自动扩容、自动修复、自动备份等。你可以通过定义自动化任务规则,并与警报规则结合起来,实现对应用程序和系统的自动化管理和运维。
总的来说,Prometheus 在项目中的应用可以帮助你实现对应用程序和系统的全面监控和管理,提高系统的稳定性、可靠性和性能。
问题2:opentelemetry相关在项目的实践(trace的协议、打点后上报)(柯莱特-外派小红书)
问题3:Promethues的metrics类型(counter、gauge、Histogram、Summary)(柯莱特-外派小红书)
8 算法
- 问题1:算法题:使用两个Goroutine,向标准输出中按顺序按顺序交替打出字母与数字,输出是a1b2c3……(百度,滴滴)
这个很容易想到用2个goruntine,2个channel实现,但是,如果只用一个channel怎么实现呢?还是有点难度的,下面看完整代码
func PrintN(n int) {
// 定义chan
run := make(chan bool)
// 定义结束chan
stop := make(chan bool, 2)
// go runtine1
go func(i int) {
for {
fmt.Printf("%d,", i)
i += 2
run <- true
run <- true
if i >= n {
stop <- true
return
}
}
}(1)
// go runtine2
go func(i int) {
for {
<-run
fmt.Printf("%d,", i)
i += 2
<-run
if i > n {
stop <- true
return
}
}
}(2)
// 监听结束信号
<-stop
<-stop
// 关闭chan
close(run)
close(stop)
}更多信息可见面试题:给一个数字n,请你用2个线程分别输出奇数和偶数,要求最终输出顺序是递增的
9 自我介绍
问题1:自我介绍、项目介绍(柯莱特-外派小红书,百度,滴滴,360,小米)
问题2:项目的业务背景(360)
问题3:k8s的源码看过么?(360)
问题4:Prometheus在项目中的监控了哪些信息?如何监控?(360)
问题5:项目中,单元测试中需要mock哪些代码?(360)
10 职业规划
- 问题1:职业规划(云平台、业务开发)(展盟)
11 面试建议
一定不要死记硬背八股文,学会结合自己的项目去总结梳理,去表达,这样才能打动面试官



