任何语言的内存管理都是基于操作系统的,因此要搞明白Go的内存管理,必须先搞清楚操作系统的内存管理。语言的内存管理主要是对操作系统的内存针对开发者做了一层封装,让开发者少关心或者不用关心内存管理相关的工作。
1 操作系统内存管理
1.1 原始的内存管理方式
我们可以把内存看成一个数组,每个数组元素的大小是 1B,也就是 8 位(bit)。CPU 通过内存地址来获取内存中的数据,内存地址可以看做成数组的游标(index)。
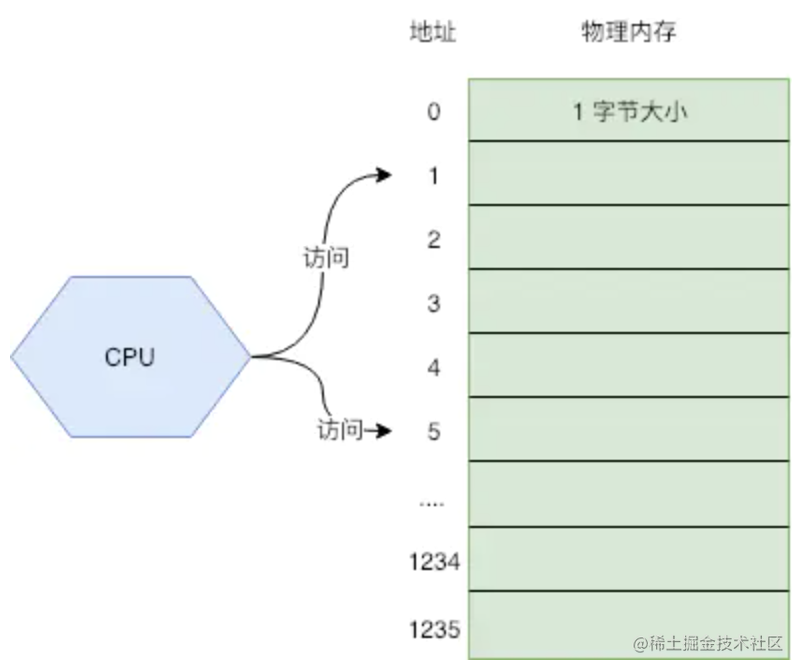
CPU 在执行指令的时候,就是通过内存地址,将物理内存上的数据载入到寄存器,然后执行机器指令。但随着发展,出现了多任务的需求,也就是希望多个任务能同时在系统上运行。这就出现了一些问题
- 内存访问冲突:程序很容易出现 bug,就是 2 或更多的程序使用了同一块内存空间,导致数据读写错乱,程序崩溃。更有一些黑客利用这个缺陷来制作病毒。
- 内存不够用:因为每个程序都需要自己单独使用的一块内存,内存的大小就成了任务数量的瓶颈。
- 程序开发成本高:你的程序要使用多少内存,内存地址是多少,这些都不能搞错,对于人来说,开发正确的程序很费脑子。
1.2虚拟内存
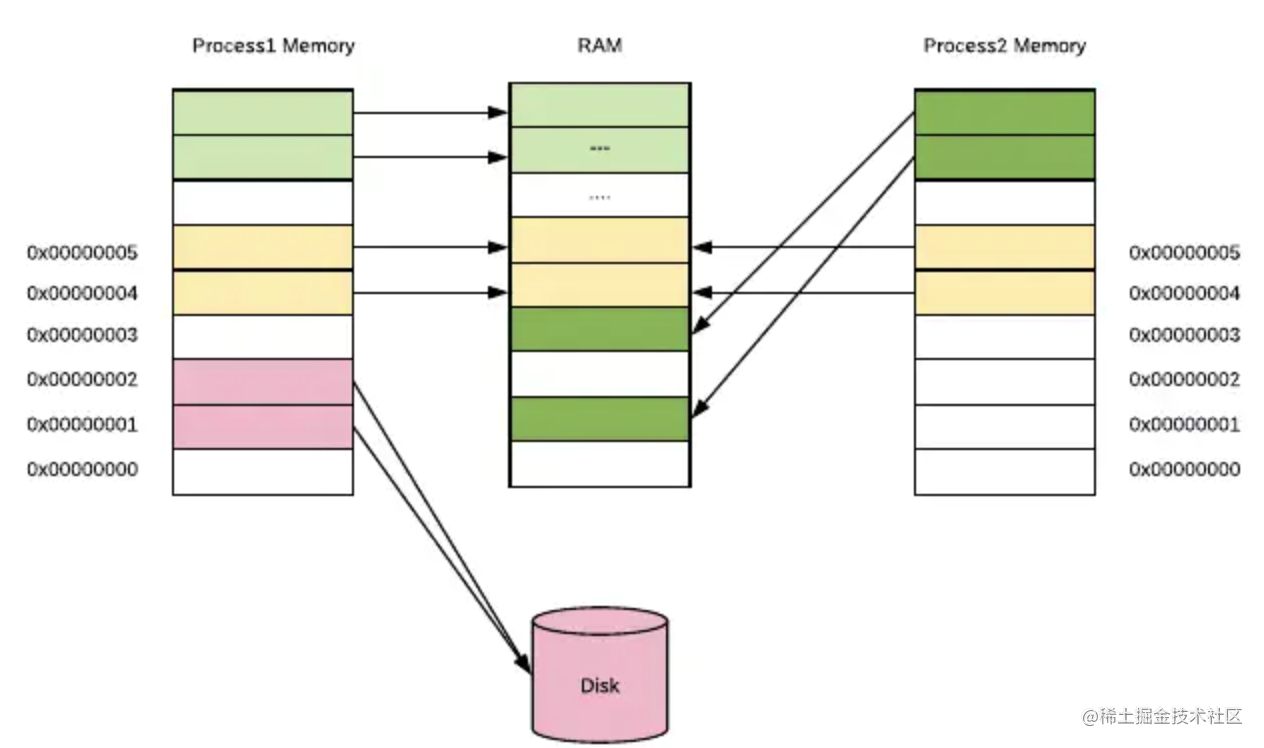
虚拟内存的出现,很好的为了解决上述的一些列问题。用户程序只能使用虚拟的内存地址来获取数据,系统会将这个虚拟地址翻译成实际的物理地址。
所有程序统一使用一套连续虚拟地址,比如 0x0000 ~ 0xffff。从程序的角度来看,它觉得自己独享了一整块内存。不用考虑访问冲突的问题。系统会将虚拟地址翻译成物理地址,从内存上加载数据。
对于内存不够用的问题,虚拟内存本质上是将磁盘当成最终存储,而主存作为了一个 cache。程序可以从虚拟内存上申请很大的空间使用,比如 1G;但操作系统不会真的在物理内存上开辟 1G 的空间,它只是开辟了很小一块,比如 1M 给程序使用。
这样程序在访问内存时,操作系统看访问的地址是否能转换成物理内存地址。能则正常访问,不能则再开辟。这使得内存得到了更高效的利用。
如下图所示,每个进程所使用的虚拟地址空间都是一样的,但他们的虚拟地址会被映射到主存上的不同区域,甚至映射到磁盘上(当内存不够用时)
虚拟内存的实现方式,大多数都是通过页表来实现的。操作系统虚拟内存空间分成一页一页的来管理,每页的大小为 4K(当然这是可以配置的,不同操作系统不一样)。磁盘和主内存之间的置换也是以页为单位来操作的。4K 算是通过实践折中出来的通用值,太小了会出现频繁的置换,太大了又浪费内存
让我们来看一下 CPU 内存访问的完整过程:
- CPU 使用虚拟地址访问数据,比如执行了 MOV 指令加载数据到寄存器,把地址传递给 MMU。
- MMU 生成 PTE 地址,并从主存(或自己的 Cache)中得到它。
- 如果 MMU 根据 PTE 得到真实的物理地址,正常读取数据。流程到此结束。
- 如果 PTE 信息表示没有关联的物理地址,MMU 则触发一个缺页异常。
- 操作系统捕获到这个异常,开始执行异常处理程序。在物理内存上创建一页内存,并更新页表。
- 缺页处理程序在物理内存中确定一个牺牲页,如果这个牺牲页上有数据,则把数据保存到磁盘上。
- 缺页处理程序更新 PTE。
- 缺页处理程序结束,再回去执行上一条指令(导致缺页异常的那个指令,也就是 MOV 指令)。这次肯定命中了。
如果物理内存不足了,数据会在主存和磁盘之间频繁交换,命中率很低,性能出现急剧下降,我们称这种现象叫内存颠簸。这时你会发现系统的 swap 空间利用率开始增高, CPU 利用率中 iowait 占比开始增高。
大多数情况下,只要物理内存够用,页命中率不会非常低,不会出现内存颠簸的情况。因为大多数程序都有一个特点,就是局部性。
局部性就是说被引用过一次的存储器位置,很可能在后续再被引用多次;而且在该位置附近的其他位置,也很可能会在后续一段时间内被引用。
前面说过计算机到处使用一级级的缓存来提升性能,归根结底就是利用了局部性的特征,如果没有这个特性,一级级的缓存不会有那么大的作用。所以一个局部性很好的程序运行速度会更快。
1.3 CPU Cache
随着技术发展,CPU 的运算速度越来越快,但内存访问的速度却一直没什么突破。最终导致了 CPU 访问主存就成了整个机器的性能瓶颈。CPU Cache 的出现就是为了解决这个问题,在 CPU 和 主存之间再加了 Cache,用来缓存一块内存中的数据,而且还不只一个,现代计算机一般都有 3 级 Cache,其中 L1 Cache 的访问速度和寄存器差不多。
现在访问数据的大致的顺序是 CPU –> L1 Cache –> L2 Cache –> L3 Cache –> 主存 –> 磁盘。从左到右,访问速度越来越慢,空间越来越大,单位空间(比如每字节)的价格越来越低。
现在存储器的整体层次结构大致如下图:
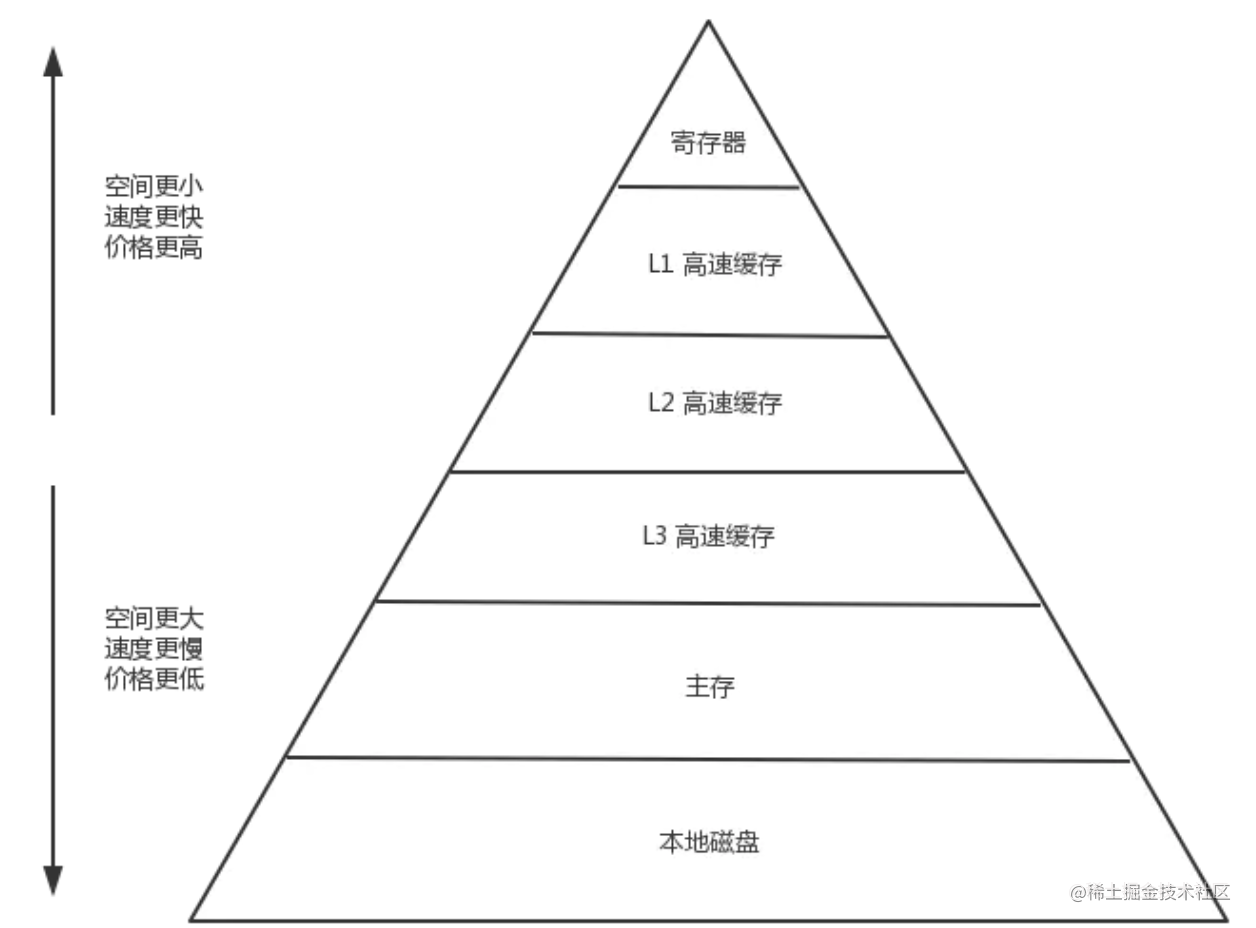
在这种架构下,缓存的命中率就更加重要了,因为系统会假定所有程序都是有局部性特征的。如果某一级出现了未命中,他就会将该级存储的数据更新成最近使用的数据。
主存与存储器之间以 page(通常是 4K) 为单位进行交换,cache 与 主存之间是以 cache line(通常 64 byte) 为单位交换的。
1.4 程序的内存布局
介绍完了操作系统内存管理,就需要了解程序的内存管理,先来看看程序的内存布局。
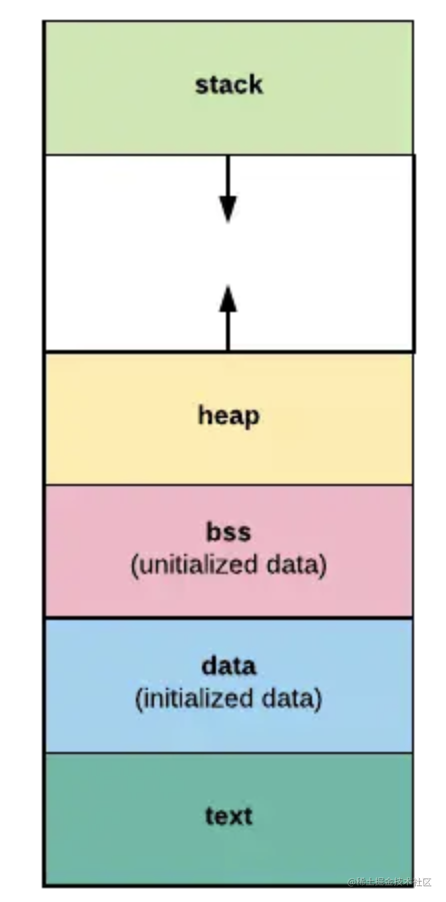
每个程序的内存分成上图几段:
- text 段:存储程序的二进制指令,及其他的一些静态内容
- data 段:用来存储已被初始化的全局变量。比如常量(const)。
- bss 段:用来存放未被初始化的全局变量。和 .data 段一样都属于静态分配,在这里面的变量数据在编译就确定了大小,不释放。
- stack 段:栈空间,主要用于函数调用时存储临时变量的。这部分的内存是自动分配自动释放的。
- heap 段:堆空间,用于动态分配,C 语言中 malloc 和 free 操作的内存就在这里;Go 语言主要靠 GC 自动管理这部分。
2 TCMalloc
TCMalloc是Thread Cache Malloc的简称,是Go内存管理的起源,Go的内存管理是借鉴了TCMalloc,因此需要先了解TCMalloc。
在Linux里,其实有不少的内存管理库,比如glibc的ptmalloc,FreeBSD的jemalloc,Google的tcmalloc等等,为何会出现这么多的内存管理库?本质都是在多线程编程下,追求更高内存管理效率:更快的分配是主要目的。
已有前提:
- 多线程将内存访问冲突和内存分配的维度降低了。每个进程都有自己的内存空间,每个线程都只能访问或者分配所属进程的内存,及进程间内存是独立的,线程间内存访问是共享的。
- 为线程预分配缓存需要进行1次系统调用,后续线程申请小内存时,从缓存分配,都是在用户态执行,没有系统调用。相当于加快了线程的内存分配速度
- 多个线程同时申请小内存时,从各自的缓存分配,访问的是不同的地址空间,无需加锁。内存访问和分配更快一点了。
2.1 如何分配定长对象
例如,我们有一个 Page 的内存,大小为 4KB,现在要以 N 字节为单位进行分配。为了简化问题,就以 16 字节为单位进行分配。
解法有很多,比如,bitmap。4KB / 16 / 8 = 32, 用 32 字节做 bitmap即可,实现也相当简单。
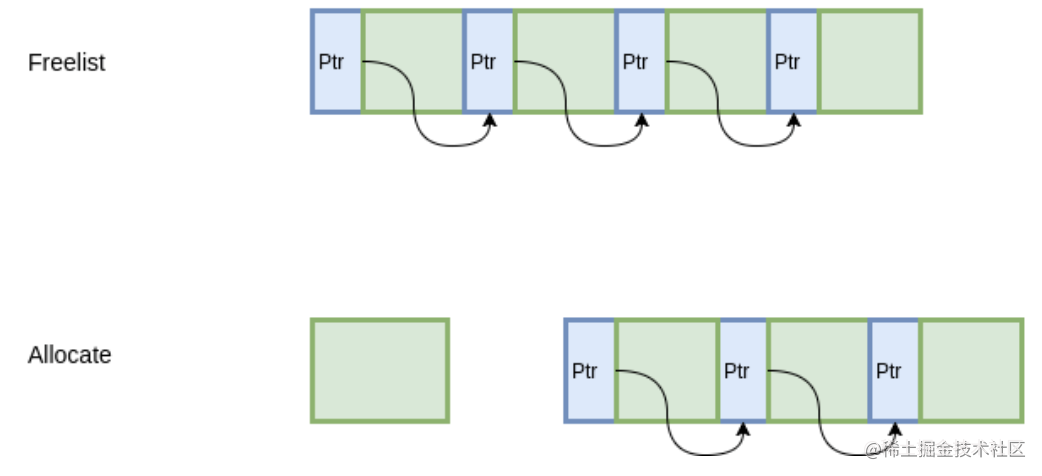
出于最大化内存利用率的目的,我们使用另一种经典的方式,freelist。将 4KB 的内存划分为 16 字节的单元,每个单元的前8个字节作为节点指针,指向下一个单元。初始化的时候把所有指针指向下一个单元;分配时,从链表头分配一个对象出去;释放时,插入到链表。
由于链表指针直接分配在待分配内存中,因此不需要额外的内存开销,而且分配速度也是相当快
2.2 如何分配变长对象
我们把问题化归成对多种定长记录的分配问题。
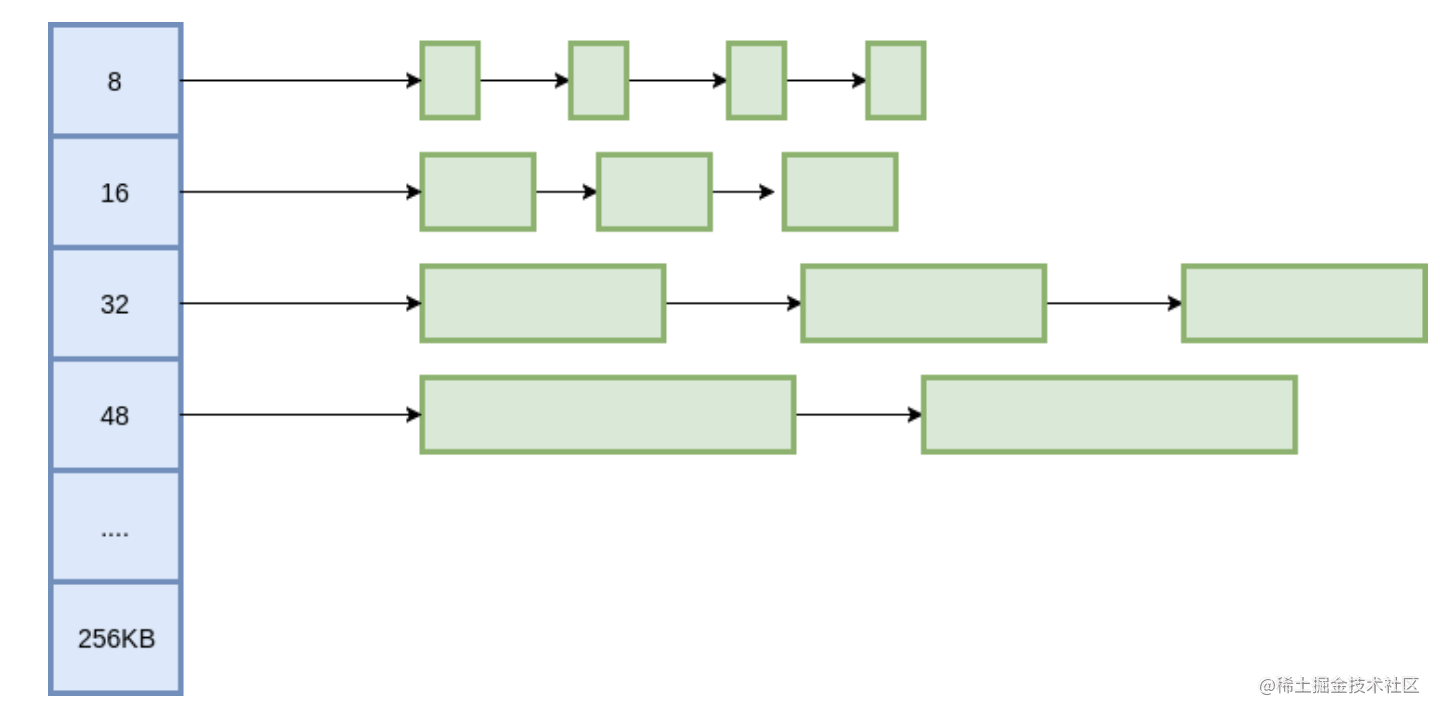
我们把所有的变长记录进行“取整”,例如分配7字节,就分配8字节,31字节分配32字节,得到多种规格的定长记录。这里带来了内部内存碎片的问题,即分配出去的空间不会被完全利用,有一定浪费。为了减少内部碎片,分配规则按照 8, 16, 32, 48, 64, 80这样子来。注意到,这里并不是简单地使用2的幂级数,因为按照2的幂级数,内存碎片会相当严重,分配65字节,实际会分配128字节,接近50%的内存碎片。而按照这里的分配规格,只会分配80字节,一定程度上减轻了问题。
大对象如何分配?
上面讲的是基于 Page,分配小于Page的对象,但是如果分配的对象大于一个 Page,我们就需要用多个 Page 来分配了:

这里提出了 Span 的概念,也就是多个连续的 Page 会组成一个 Span,在 Span 中记录起始 Page 的编号,以及 Page 数量。
分配对象时,大的对象直接分配 Span,小的对象从 Span 中分配。
Span如何分配?
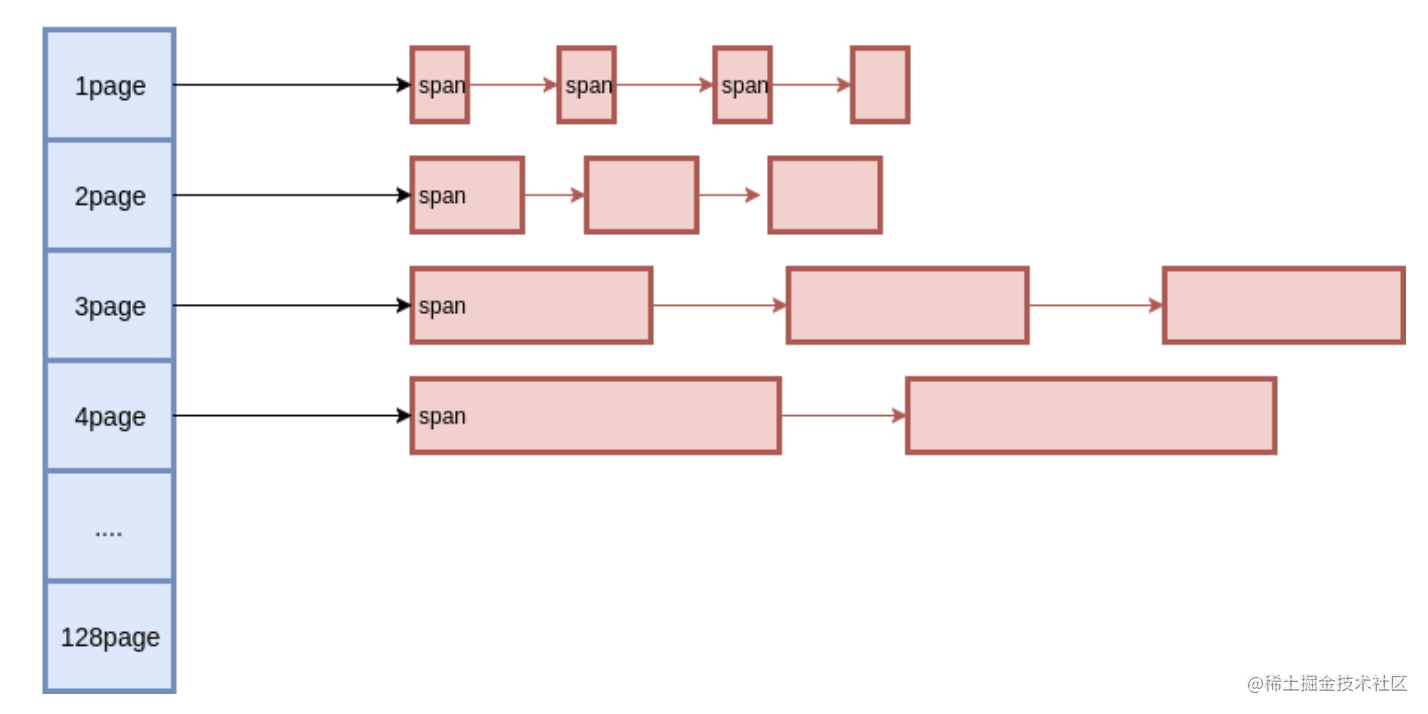
与小对象内存管理一样,还是用多种定长 Page 来实现变长 Page 的分配,初始时只有 128 Page 的 Span,如果要分配 1 个 Page 的 Span,就把这个 Span 分裂成两个,1 + 127,把127再记录下来。对于 Span 的回收,需要考虑Span的合并问题,否则在分配回收多次之后,就只剩下很小的 Span 了,也就是带来了外部碎片 问题。
为此,释放 Span 时,需要将前后的空闲 Span 进行合并,当然,前提是它们的 Page 要连续。
问题来了,如何知道前后的 Span 在哪里?
从Page到Span的映射
由于 Span 中记录了起始 Page,也就是知道了从 Span 到 Page 的映射,那么我们只要知道从 Page 到 Span 的映射,就可以知道前后的Span 是什么了。
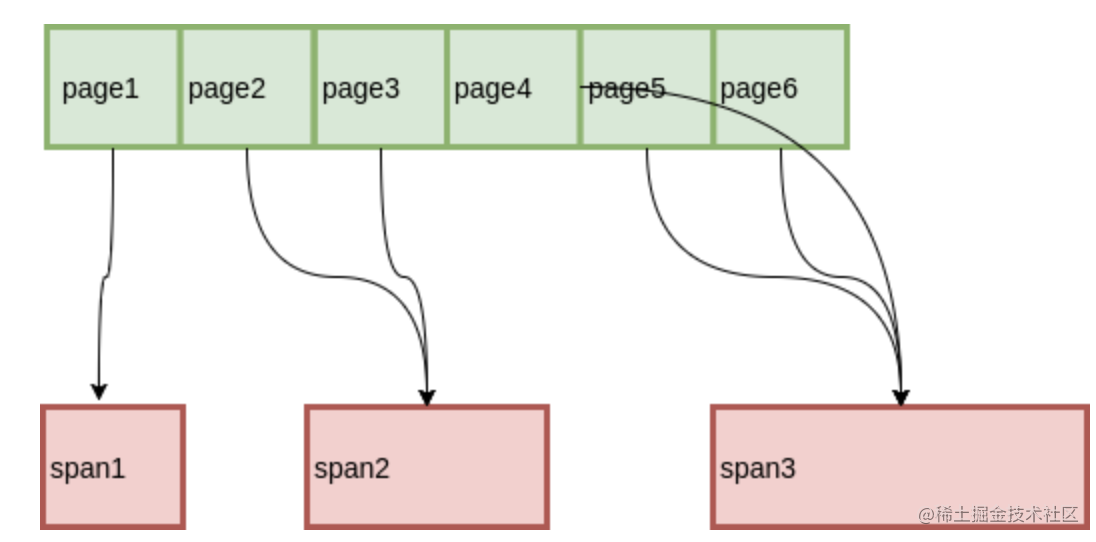
最简单的一种方式,用一个数组记录每个Page所属的 Span,而数组索引就是 Page ID。这种方式虽然简洁明了,但是在 Page 比较少的时候会有很大的空间浪费。
为此,我们可以使用 RadixTree 这种数据结构,用较少的空间开销,和不错的速度来完成这件事
至此,我们已经实现了Page的内存分配(通过span方式)和管理(通过合并span)
2.3 全局对象管理
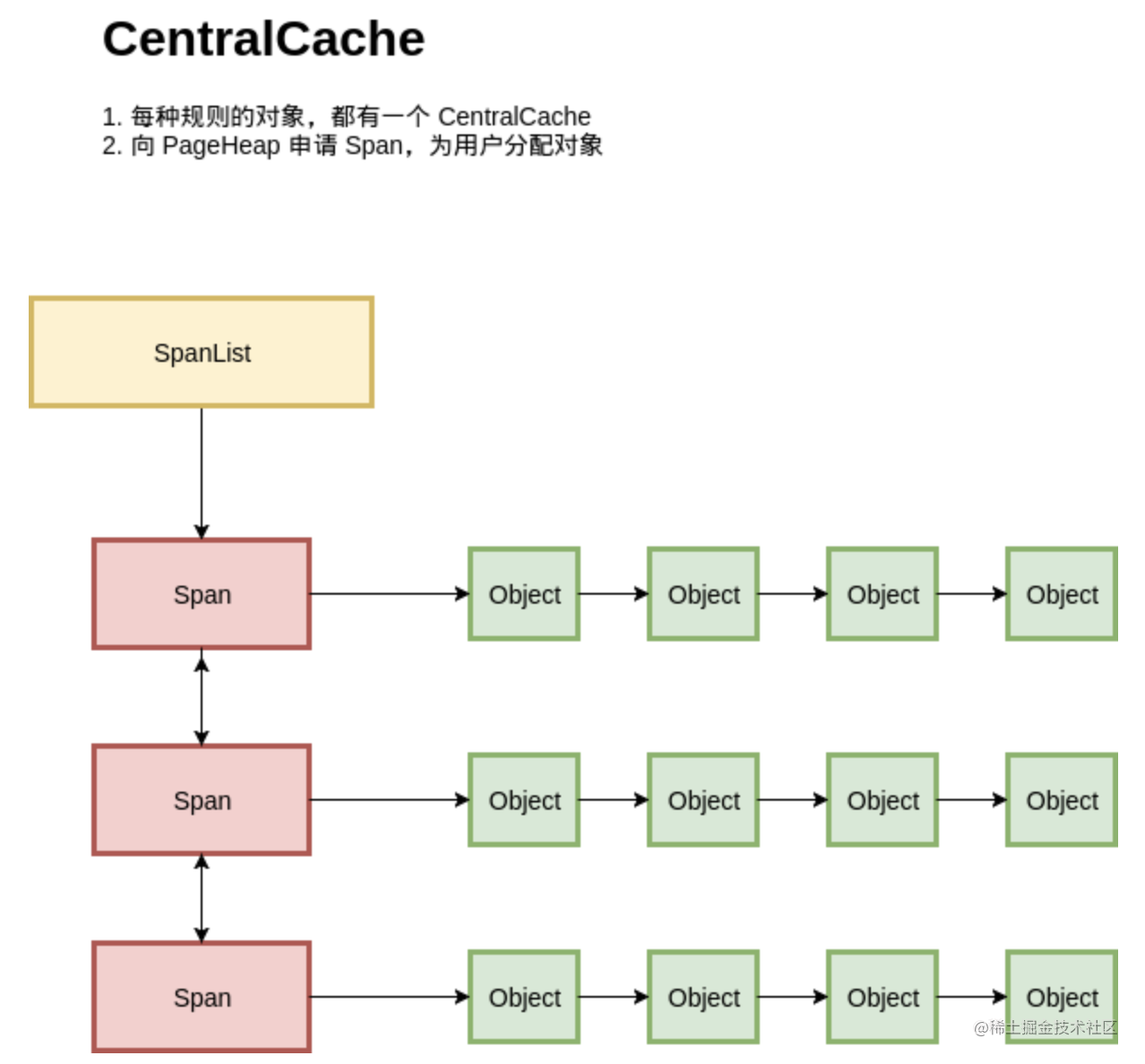
按照上述,程序的对象管理可以用上图描述。每种规格的对象,都从不同的 Span 进行分配;每种规则的对象都有一个独立的内存分配单元:CentralCache。在一个CentralCache 内存,我们用链表把所有 Span 组织起来,每次需要分配时就找一个 Span 从中分配一个 Object;当没有空闲的 Span 时,就从 PageHeap 申请 Span。
看起来基本满足功能,但是这里有一个严重的问题,在多线程的场景下,所有线程都从CentralCache 分配的话,竞争可能相当激烈。
因此,设计了ThreadCache。将小对象管理交给ThreadCache
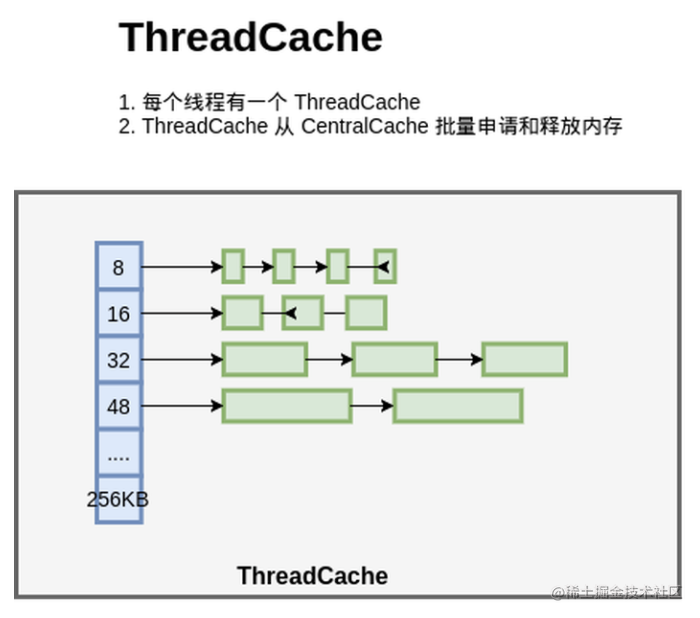
整个内存管理模型如下图:
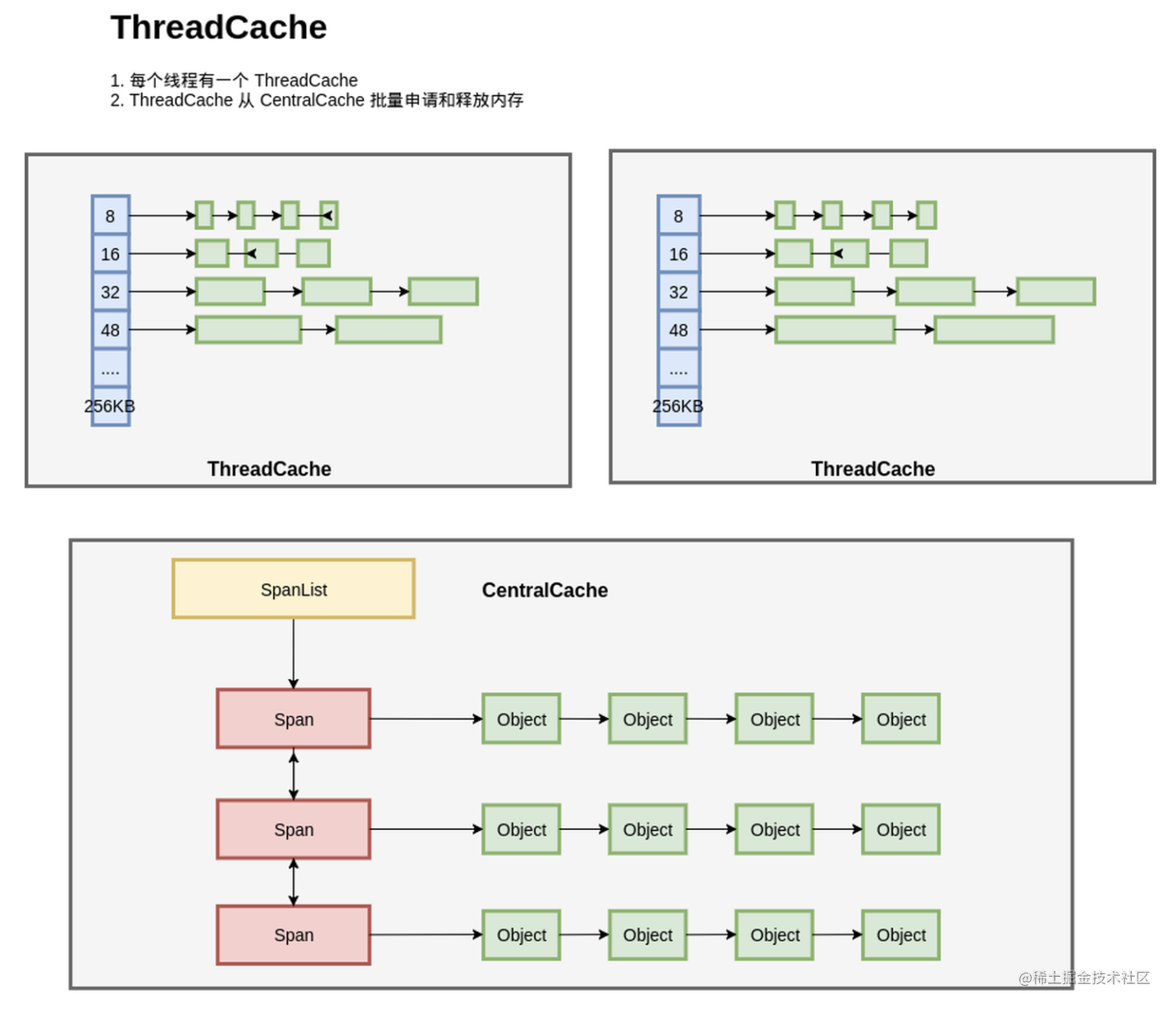
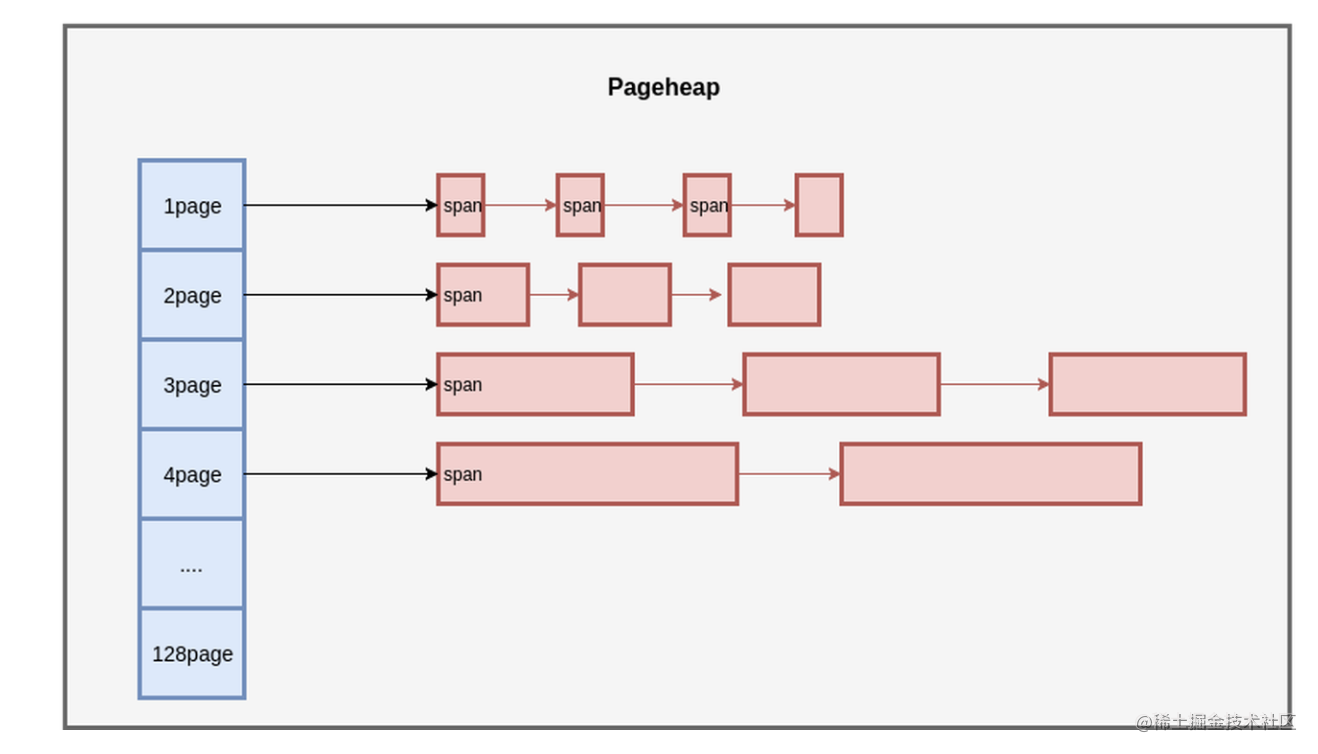
每个线程都一个线程局部的 ThreadCache,按照不同的规格,维护了对象的链表;如果ThreadCache 的对象不够了,就从 CentralCache 进行批量分配;如果 CentralCache 依然没有,就从PageHeap申请Span;如果 PageHeap没有合适的 Page,就只能从操作系统申请了。
在释放内存的时候,ThreadCache依然遵循批量释放的策略,对象积累到一定程度就释放给 CentralCache;CentralCache发现一个 Span的内存完全释放了,就可以把这个 Span 归还给 PageHeap;PageHeap发现一批连续的Page都释放了,就可以归还给操作系统。
重新解释一下上图中的三个模块:
- ThradCache:分配和管理程序的小对象内存。它是线程私有的,内存访问和分配不需要加锁。内存不够了像CentralCache申请一个span.只能申请很小的对象。
- CentralCache:分配和管理程序的小对象内存。如果内存不够了则从PageHeap申请Span
- PageHeap:管理Span。主要是page到span的映射。如果span不够则向操作系统申请,如果发现有一片连续的span都释放了则归还给操作系统。
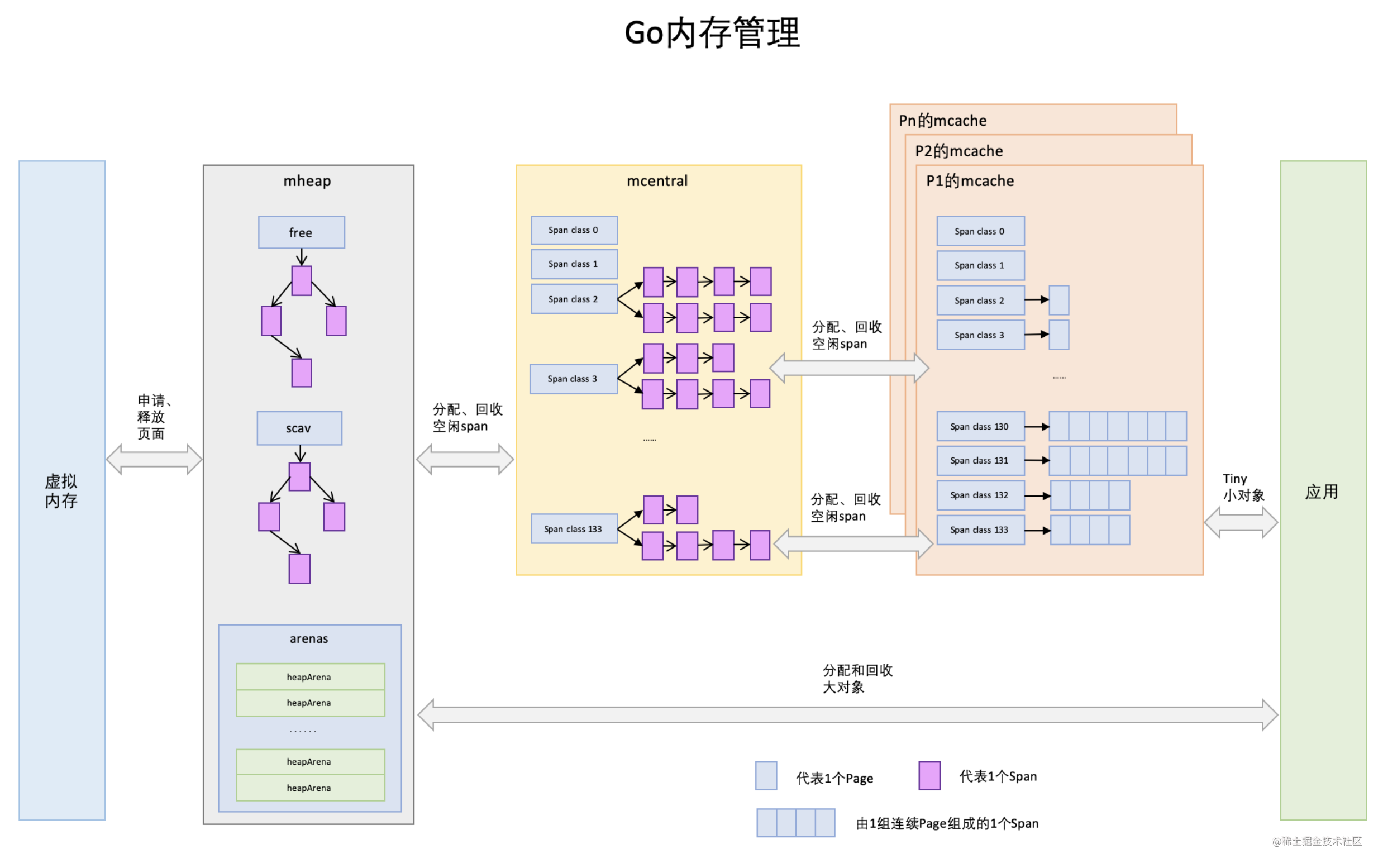
3 GO内存管理
Go语言内置运行时(就是runtime),抛弃了传统的内存分配方式,改为自主管理。这样可以自主地实现更好的内存使用模式,比如内存池、预分配等等。这样,不会每次内存分配都需要进行系统调用。
Golang运行时的内存分配算法主要源自 Google 为 C 语言开发的TCMalloc算法,全称Thread-Caching Malloc。核心思想就是把内存分为多级管理,从而降低锁的粒度。它将可用的堆内存采用二级分配的方式进行管理:每个线程都会自行维护一个独立的内存池,进行内存分配时优先从该内存池中分配,当内存池不足时才会向全局内存池申请,以避免不同线程对全局内存池的频繁竞争。
3.1 基本概念
Go在程序启动的时候,会先向操作系统申请一块内存(注意这时还只是一段虚拟的地址空间,并不会真正地分配内存),切成小块后自己进行管理。
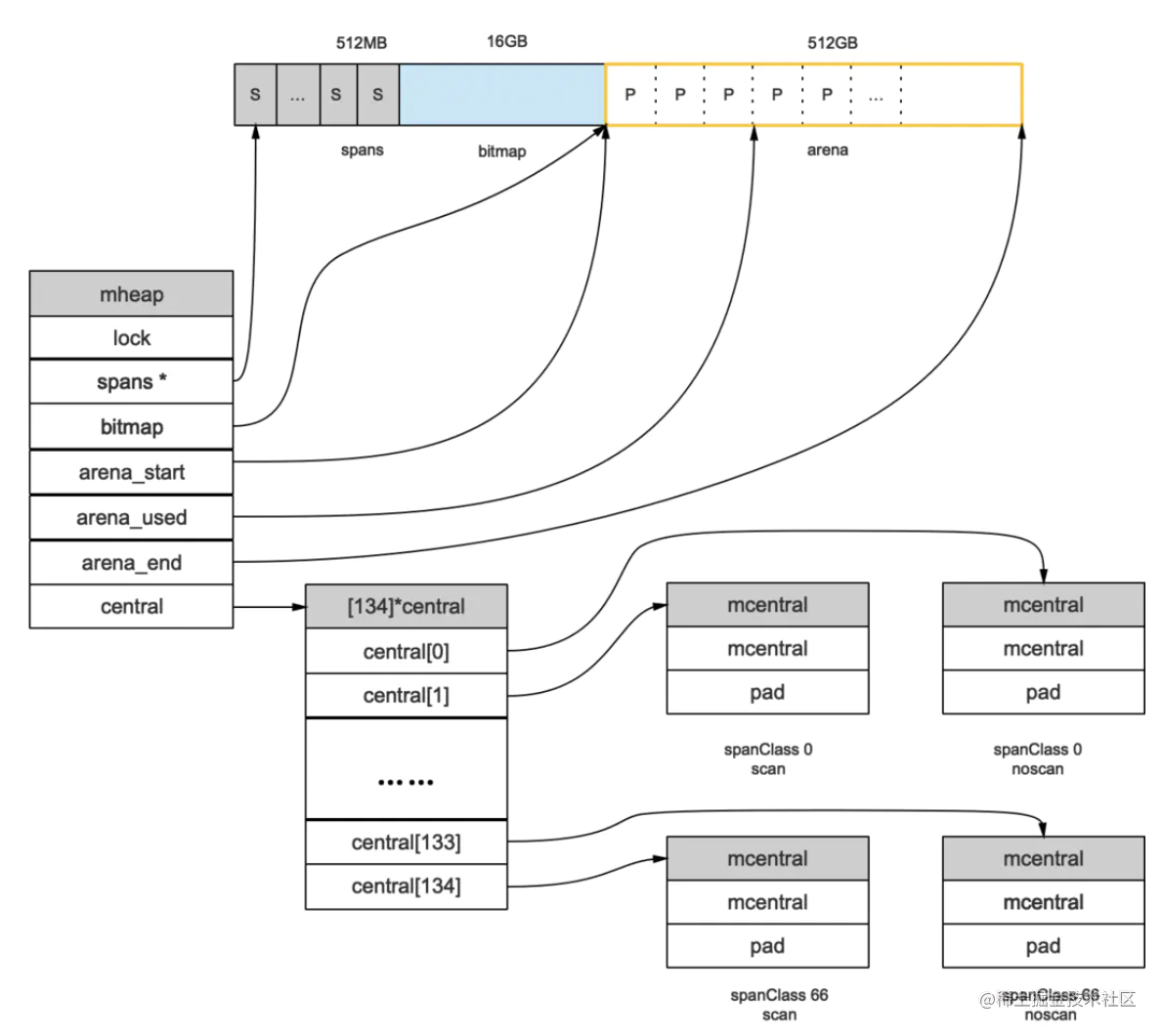
申请到的内存块被分配了三个区域,在X64上分别是512MB,16GB,512GB大小。
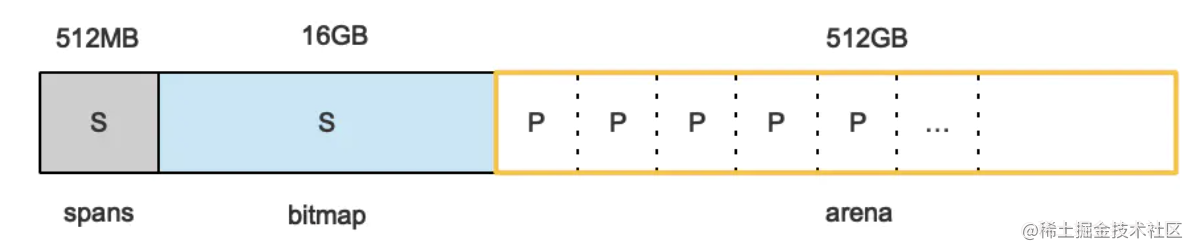
arena区域:就是我们所谓的堆区,Go动态分配的内存都是在这个区域,它把内存分割成8KB大小的页,一些页组合起来称为mspan。
bitmap区域:标识arena区域哪些地址保存了对象,并且用4bit标志位表示对象是否包含指针、GC标记信息。bitmap中一个byte大小的内存对应arena区域中4个指针大小(指针大小为 8B )的内存,所以bitmap区域的大小是512GB/(4*8B)=16GB。
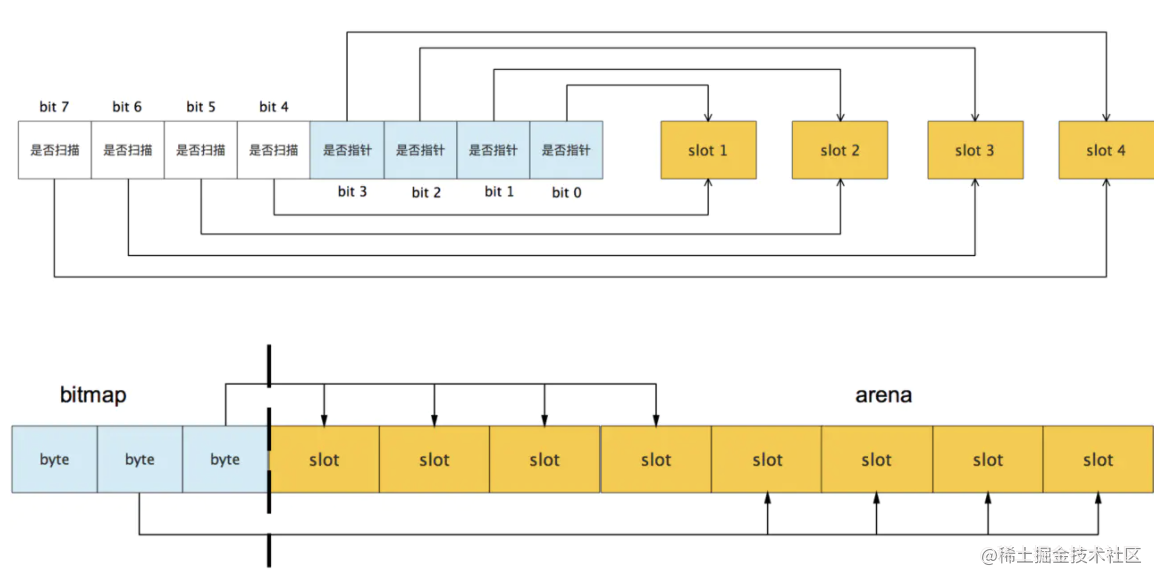
从上图其实还可以看到bitmap的高地址部分指向arena区域的低地址部分,也就是说bitmap的地址是由高地址向低地址增长的。
spans区域:存放mspan的指针(多个页合并成一个span).每个指针对应一页,所以spans区域的大小就是512GB/8KB*8B=512MB。除以8KB是计算arena区域的页数,而最后乘以8是计算spans区域所有指针的大小。创建mspan的时候,按页填充对应的spans区域,在回收object时,根据地址很容易就能找到它所属的mspan
3.1.1 内存管理单元
mspan:Go中内存管理的基本单元,是由一片连续的8KB的页组成的大块内存。注意,这里的页和操作系统本身的页并不是一回事,它一般是操作系统页大小的几倍。一句话概括:mspan是一个包含起始地址、mspan规格、页的数量等内容的双端链表.
每个mspan按照它自身的属性Size Class的大小分割成若干个object,每个object可存储一个对象。并且会使用一个位图来标记其尚未使用的object。属性Size Class决定object大小,而mspan只会分配给和object尺寸大小接近的对象,也就是每个span里面只能分配固定大小的object。当然,对象的大小要小于object大小。还有一个概念:Span Class,它和Size Class的含义差不多:
Span_Class = Size_Class * 2 这是因为其实每个 Size Class有两个mspan,也就是有两个Span Class。其中一个分配给含有指针的对象,另一个分配给不含有指针的对象。这会给垃圾回收机制带来利好,后面垃圾回收再谈。
Go1.9.2里mspan的Size Class共有67种,每种mspan分割的object大小是8*2n的倍数,这个是写死在代码里的:
// path: /usr/local/go/src/runtime/sizeclasses.go
const _NumSizeClasses = 67
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536,1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}根据mspan的Size Class可以得到它划分的object大小。 比如Size Class等于3,object大小就是32B。 32B大小的object可以存储对象大小范围在17B~32B的对象。而对于微小对象(小于16B),分配器会将其进行合并,将几个对象分配到同一个object中。
数组里最大的数是32768,也就是32KB,超过此大小就是大对象了,它会被特别对待,这个稍后会再介绍。顺便提一句,类型Size Class为0表示大对象,它实际上直接由堆内存分配,而小对象都要通过mspan来分配.
mspan结构
// path: /usr/local/go/src/runtime/mheap.go
type mspan struct {
//链表前向指针,用于将span链接起来
next *mspan
//链表前向指针,用于将span链接起来
prev *mspan
// 起始地址,也即所管理页的地址
startAddr uintptr
// 管理的页数
npages uintptr
// 块个数,表示有多少个块可供分配
nelems uintptr
//分配位图,每一位代表一个块是否已分配
allocBits *gcBits
// 已分配块的个数
allocCount uint16
// class表中的class ID,和Size Classs相关
spanclass spanClass
// class表中的对象大小,也即块大小
elemsize uintptr
}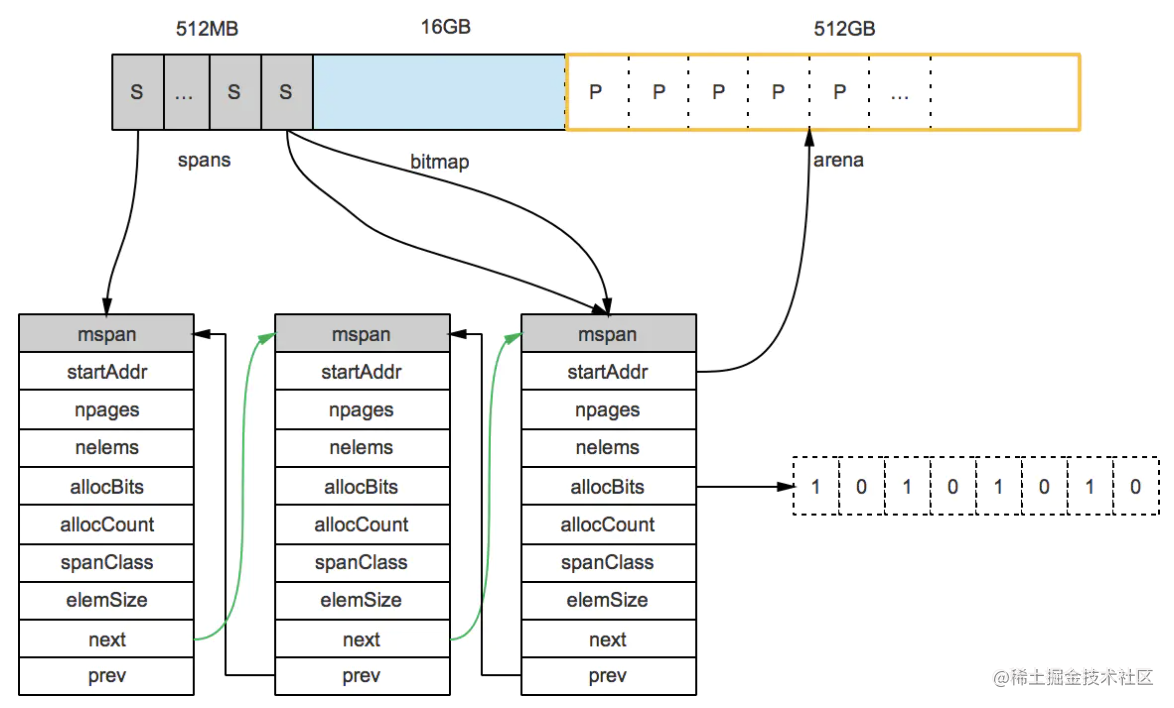
上图可以看到有两个S指向了同一个mspan,因为这两个S指向的P是同属一个mspan的。所以,通过arena上的地址可以快速找到指向它的S,通过S就能找到mspan,回忆一下前面我们说的mspan区域的每个指针对应一页。
假设最左边第一个mspan的Size Class等于10,根据前面的class_to_size数组,得出这个msapn分割的object大小是144B,算出可分配的对象个数是8KB/144B=56.89个,取整56个,所以会有一些内存浪费掉了,Go的源码里有所有Size Class的mspan浪费的内存的大小;再根据class_to_allocnpages数组,得到这个mspan只由1个page组成;假设这个mspan是分配给无指针对象的,那么spanClass等于20。
startAddr直接指向arena区域的某个位置,表示这个mspan的起始地址,allocBits指向一个位图,每位代表一个块是否被分配了对象;allocCount则表示总共已分配的对象个数。
这样,左起第一个mspan的各个字段参数就如下图所示:

3.1.2 内存管理组件
内存分配由内存分配器完成。分配器由3种组件构成:mcache, mcentral, mheap。
mcache:每个goroutine都会绑定一个mcache,本地缓存可用的mspan资源,这样就可以直接给Goroutine分配,因为不存在多个Goroutine竞争的情况,所以不会消耗锁资源。
mcache的结构体定义:
//path: /usr/local/go/src/runtime/mcache.go
type mcache struct {
alloc [numSpanClasses]*mspan
}
numSpanClasses = _NumSizeClasses << 1mcache用Span Classes作为索引管理多个用于分配的mspan,它包含所有规格的mspan。它是_NumSizeClasses的2倍,也就是67*2=134,为什么有一个两倍的关系,前面我们提到过:为了加速之后内存回收的速度,数组里一半的mspan中分配的对象不包含指针,另一半则包含指针.
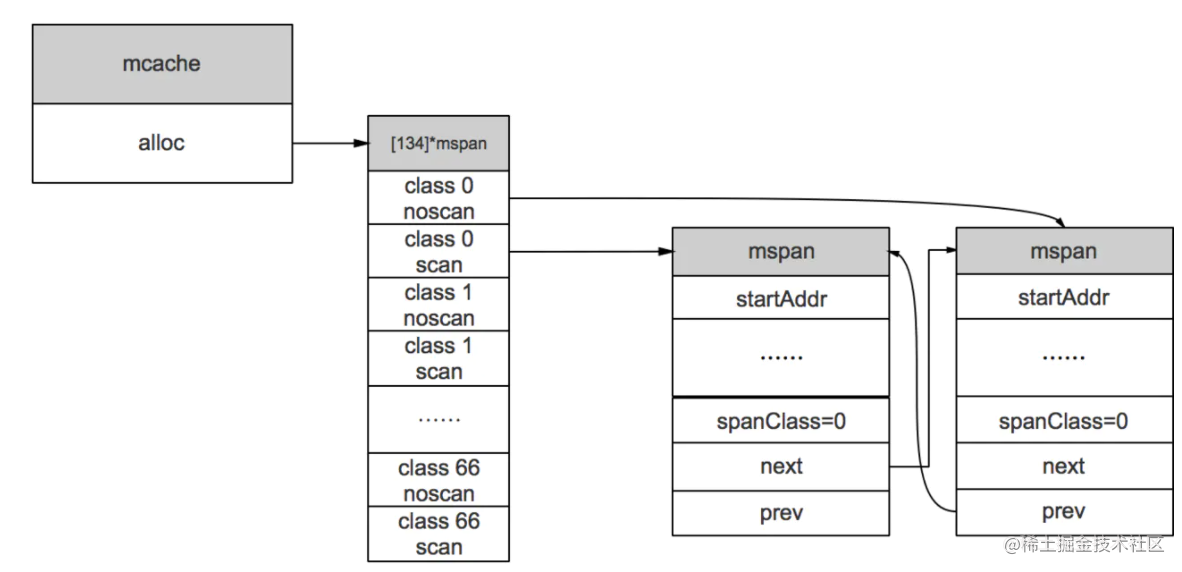
mcache在初始化的时候是没有任何mspan资源的,在使用过程中会动态地从mcentral申请,之后会缓存下来。当对象小于等于32KB大小时,使用mcache的相应规格的mspan进行分配。
mcentral:为所有mcache提供切分好的mspan资源。每个central保存一种特定大小的全局mspan列表,包括已分配出去的和未分配出去的。 每个mcentral对应一种mspan,而mspan的种类导致它分割的object大小不同。当goroutine的mcache中没有合适(也就是特定大小的)的mspan时就会从mcentral获取.
mcentral被所有的goroutine共同享有,存在多个Goroutine竞争的情况,因此会消耗锁资源。结构体定义:
//path: /usr/local/go/src/runtime/mcentral.go
type mcentral struct {
// 互斥锁
lock mutex
// 规格
sizeclass int32
// 尚有空闲object的mspan链表
nonempty mSpanList
// 没有空闲object的mspan链表,或者是已被mcache取走的msapn链表
empty mSpanList
// 已累计分配的对象个数
nmalloc uint64
}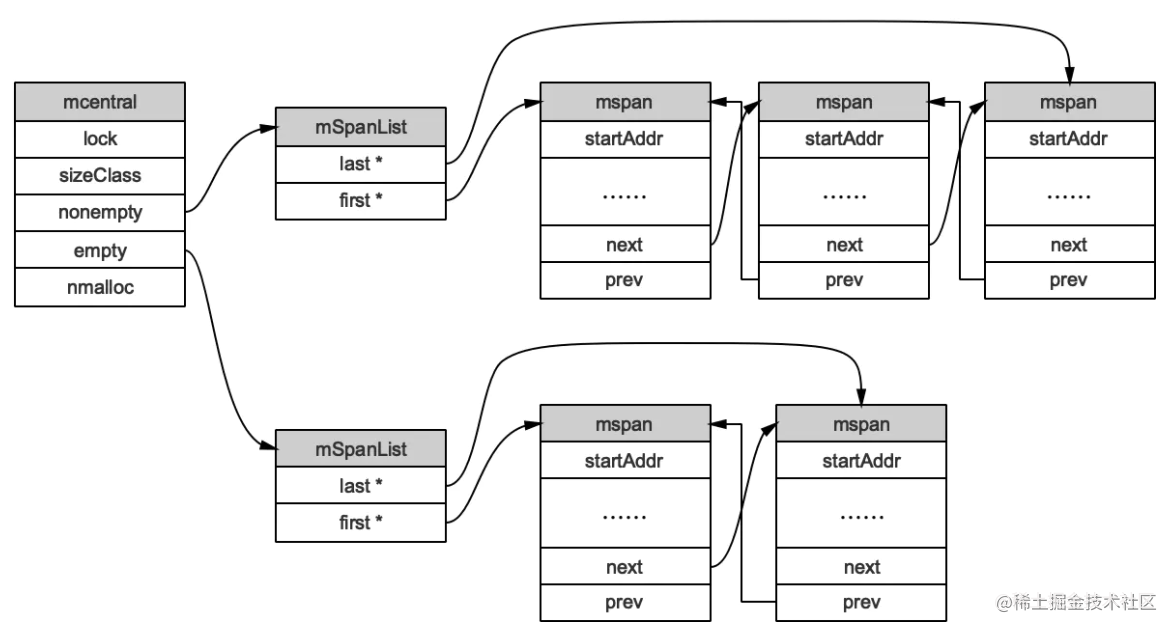
empty表示这条链表里的mspan都被分配了object,或者是已经被cache取走了的mspan,这个mspan就被那个工作线程独占了。而nonempty则表示有空闲对象的mspan列表。每个central结构体都在mheap中维护.
简单说下mcache从mcentral获取和归还mspan的流程:
- 获取 加锁;从nonempty链表找到一个可用的mspan;并将其从nonempty链表删除;将取出的mspan加入到empty链表;将mspan返回给工作线程;解锁。
- 归还 加锁;将mspan从empty链表删除;将mspan加入到nonempty链表;解锁。
mheap:代表Go程序持有的所有堆空间,Go程序使用一个mheap的全局对象_mheap来管理堆内存。
当mcentral没有空闲的mspan时,会向mheap申请。而mheap没有资源时,会向操作系统申请新内存。mheap主要用于大对象的内存分配,以及管理未切割的mspan,用于给mcentral切割成小对象。
同时我们也看到,mheap中含有所有规格的mcentral,所以,当一个mcache从mcentral申请mspan时,只需要在独立的mcentral中使用锁,并不会影响申请其他规格的mspan。
mheap结构体定义:
//path: /usr/local/go/src/runtime/mheap.go
type mheap struct {
lock mutex
// spans: 指向mspans区域,用于映射mspan和page的关系
spans []*mspan
// 指向bitmap首地址,bitmap是从高地址向低地址增长的
bitmap uintptr
// 指示arena区首地址
arena_start uintptr
// 指示arena区已使用地址位置
arena_used uintptr
// 指示arena区末地址
arena_end uintptr
central [67*2]struct {
mcentral mcentral
pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte
}
}
3.2 对象分配
Go的内存分配器在分配对象时,根据对象的大小,分成三类:
- 小对象(小于等于16B):使用mcache的tiny分配器分配;
- 一般对象(大于16B,小于等于32KB):首先计算对象的规格大小,然后使用mcache中相应规格大小的mspan分配;如果mcache没有相应规格大小的mspan,则向mcentral申请;如果mcentral没有相应规格大小的mspan,则向mheap申请;如果mheap中也没有合适大小的mspan,则向操作系统申请
- 大对象(大于32KB):直接从mheap上分配
一个变量是在堆上分配,还是在栈上分配,是经过编译器的逃逸分析之后得出的结论。
3.2.1 什么是逃逸分析
通俗来讲,当一个对象的指针被多个方法或线程引用时,我们称这个指针发生了逃逸.
3.2.2 为什么要逃逸分析
通过逃逸分析,可以尽量把那些不需要分配到堆上的变量直接分配到栈上,堆上的变量少了,会减轻分配堆内存的开销,同时也会减少gc的压力,提高程序的运行速度。也就是说,通过逃逸分析,将对象对象合理地分配到它应该待的地方。
3.2.3 逃逸分析是怎么完成的
编译器会分析代码的特征和代码生命周期,Go中的变量只有在编译器可以证明在函数返回后不会再被引用的,才分配到栈上,其他情况下都是分配到堆上。
简单来说,编译器会根据变量是否被外部引用来决定是否逃逸:
- 如果函数外部没有引用,则优先放到栈中;如果在函数内部定义了一个很大的数组,需要申请的内存过大,超过了栈的存储能力,就会被分配到堆上,或者栈空间用完了,则内部函数也会被分配到堆上。
- 如果函数外部存在引用,则必定放到堆中;
堆上动态分配内存比栈上静态分配内存,开销大很多。
变量分配在栈上需要能在编译期确定它的作用域,否则会分配到堆上。
Go编译器会在编译期对考察变量的作用域,并作一系列检查,如果它的作用域在运行期间对编译器一直是可知的,那么就会分配到栈上。
简单来说,编译器会根据变量是否被外部引用来决定是否逃逸。
4 总结
本文从操作系统内存管理、GO内存管理三个方面介绍了Go语言的内存分配,另外一篇文章《Go垃圾回收》,都只是从大体上介绍了一下,并没有详细讲解。如果需要更学习更详细的细节可评论,后续整理一下。
5 参考
【1】图解 TCMalloc
【2】tcmalloc 介绍
【3】Golang 内存管理
【4】系统内存管理
【5】TCMalloc:线程缓存Malloc
【6】Go内存分配那些事,就这么简单!
【7】图解Go语言内存分配
【8】Golang之变量去哪儿
【9】对象分配流程图
【10】进程里面的堆和栈
【11】GO内存管理



